10. 第10回 教師なし学習
![]()
※Web上ではテーブルや記号など一部LaTeXが反映されず見にくくなってしまっていますが、Google Colabだとちゃんと見えます。
10.1. はじめに
ここまで扱ってきた線形モデルでは、収穫量を肥料の量や圃場効果から説明する様な形で、応答変数\((Y)\)を説明変数\((X_1, X_2, ... X_k)\)で説明するモデルを構築してきました。
$収穫量(Y) = \beta_0 + 肥料の効果(X_1) + 圃場(X_2)$
この様なモデルを作る事が出来れば、肥料や圃場の情報から収穫量を予測する事が出来ます。
本項では、観察データにおいて、特徴(説明変数)\(X_1, X_2, ..., X_k\)のみ得られた場合の統計手法について扱います。
この場合、応答変数\(Y\)を持たないので、何かを予測することは目的にはなりません。
観測された特徴\(X_1, X_2, ..., X_k\)について調べることで、データを可視化したり、観測値をグループ分けすることで何か知見を得ることが目的になります。
この様な状況では教師なし学習と呼ばれる技術が用いられます。
そこで、教師あり学習・教師なし学習の違いや、教師なし学習でよく用いられる主成分分析やクラスタリングと呼ばれる手法について学びます。
10.2. 教師あり学習・教師なし学習
大量のデータからパターンやルールを学習し、未知のデータに対して予測や判断を行う技術を機械学習と呼びます。
教師あり学習と教師なし学習は、機械学習における2つの主要な手法の分類になります。
データに正解があるかどうかで区別され、教師あり学習は正解が与えられたデータで予測モデルを学習させ、教師なし学習は、正解の与えられていないデータからパターンや構造を発見します。
10.2.1. 教師あり学習
教師あり学習では、データに正解を与えた状態で予測モデルを構築します。
これまで線形回帰などで量的な形質を説明したり、一般化線形モデルを用いて質的な形質を説明するモデルを構築しましたが、これは教師あり学習になります。
このモデルを用いて新しいデータの正解を予測したり、分類することが目的になります。

例えば線形回帰で予測を行う場合だと、
下記の様な、与えた肥料の量・気温毎の収穫量のデータが与えられているときに、
このデータから回帰予測式を作り、肥料の量と気温から収穫量を予測してみます。
[ ]:
# データの読み込み
data <- read.csv("https://raw.githubusercontent.com/slt666666/biostatistics_text_wed/refs/heads/main/source/_static/data/chapter10_lm.csv")
head(data)
| fertilizer | temperature | yield | |
|---|---|---|---|
| <int> | <int> | <dbl> | |
| 1 | 100 | 17 | 239.6667 |
| 2 | 100 | 16 | 250.5455 |
| 3 | 200 | 16 | 241.7778 |
| 4 | 200 | 18 | 270.0000 |
| 5 | 300 | 17 | 261.8889 |
| 6 | 300 | 15 | 243.8889 |
回帰分析はlm関数で実施できるので、まずは回帰式を作成してみます。
result <- lm(従属変数 ~ 説明変数1 + 説明変数2, data = data)
summary(result)
[ ]:
# lm関数で回帰分析を実施
result <- lm(yield ~ fertilizer + temperature, data=data)
summary(result)
Call:
lm(formula = yield ~ fertilizer + temperature, data = data)
Residuals:
Min 1Q Median 3Q Max
-29.6342 -14.0400 0.1796 18.0513 27.6457
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 58.60258 18.71947 3.131 0.00364 **
fertilizer 0.13885 0.03973 3.495 0.00137 **
temperature 10.32665 0.77280 13.363 7.24e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 19.46 on 33 degrees of freedom
Multiple R-squared: 0.8516, Adjusted R-squared: 0.8426
F-statistic: 94.66 on 2 and 33 DF, p-value: 2.141e-14
これで\(収穫量 = 58.60258 + 肥料の量 \times 0.13885 + 気温 \times 10.32665\)という予測式が出来たので、
例えば肥料の量\(200g\)、気温\(25\)度の時の収穫量は…
[ ]:
# 肥料が200g, 気温25度の収穫量を回帰式から求める
58.60258 + 200 * 0.13885 + 25 * 10.32665
と予測できます。
教師あり学習は数値的な予測だけではなく、分類を行う場合もあります。

これが教師あり学習になります。本講義では線形モデルを主に扱いましたが、教師あり学習を行う方法には様々な手法が存在しており、線形モデルはその1つに過ぎません。
基本的な手法は下記の本等で学ぶ事が出来ます。
https://www.statlearning.com/ (英語だと無料) (日本語訳は`Rによる統計的学習入門 <https://www.asakura.co.jp/detail.php?book_code=12224&srsltid=AfmBOopvxX3GAJdDoOamTSdigYybF2TpVUfh8wqSPHsJcW5r5yXMwVAz>`__)
個人的には検定等と比べて非常に面白い分野・技術だと思っているので、興味があれば見てみてください。
10.2.2. 教師なし学習
一方、教師なし学習とは、データに正解を与えない状態で学習させる手法になります。
先ほどの診断の例で考えてみると、何の症例かは不明だとしても、体温や白血球数等の情報から得られたデータをグループ分けすることで、どの様なパターンの症状の人がいるのかを調べたりします。

多種類のデータを集約する手法である主成分分析や、データ間の類似度に基づいて、データをグループ分けする手法であるクラスタリングが該当します。
本講義では扱いませんが、GAN(敵対的生成ネットワーク)なども教師なし学習の技術の1つです。
生物学において、教師なし学習が活用される例としては、
ある処理を行った生物の、遺伝子の発現データを集約して、多数の遺伝子をグループ分けしたり、
ゲノム情報に基づく種のクラスタリングなどが挙げられます。

10.3. 主成分分析
まずは教師なし学習の代表的な手法である主成分分析を扱います。
主成分分析は、ざっくりと言うと、複数の説明変数を1つ1つ独立に扱うのではなく、出来るだけ情報を失わないようにまとめて少ない変数に変換して取り扱うことを試みる分析手法になります。
例えば
\(y = a_1x_1 + a_2x_2 + a_3x_3 + ... + a_{100}x_{100}\)
と表されるものを、
\(y = b_1z_1 + b_2z_2 + b_3z_3\)
と大量の変数\(x\)をいくつかの主成分\(z\)にまとめて、よりシンプルな式にしていくイメージです。
上式だと第1主成分、第2主成分、第3主成分で式をまとめている形になります。
主成分分析はデータを可視化する際や、多重共線性が生じている際の重回帰分析において強力な手法となります。
まずは具体例で見ていきます。
下記に178種類の様々なワインに含まれる13の成分の量を測定したデータがあります。
Alcohol:アルコール, Malic acid:リンゴ酸, Ash:灰分, Alcalinity of ash:灰分アルカリ度, Magnesium:マグネシウム, Total phenols:総フェノール, Flavanoids:フラバノイド, Nonflavanoid phenols:非フラバノイドフェノール , Proanthocyanins:プロアントシアニン, Color intensity:色の濃さ, Hue:色相, OD280/OD315 of diluted wines:希釈したワインのOD280/OD315, Proline:プロリン
これらの成分を基にして、178種のワインをいくつかのグループに分けようと考えたとします。
[ ]:
# ワインの成分データを読み込む
data <- read.csv("https://raw.githubusercontent.com/slt666666/biostatistics_text_wed/refs/heads/main/source/_static/data/chapter10_wine_unknown.csv")
head(data)
| Alcohol | Malic.acid | Ash | Alcalinity.of.ash | Magnesium | Total.phenols | Flavanoids | Nonflavanoid.phenols | Proanthocyanins | Color.intensity | Hue | OD.diluted.wines | Proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <int> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <int> | |
| 1 | 14.23 | 1.71 | 2.43 | 15.6 | 127 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065 |
| 2 | 13.20 | 1.78 | 2.14 | 11.2 | 100 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050 |
| 3 | 13.16 | 2.36 | 2.67 | 18.6 | 101 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185 |
| 4 | 14.37 | 1.95 | 2.50 | 16.8 | 113 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480 |
| 5 | 13.24 | 2.59 | 2.87 | 21.0 | 118 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735 |
| 6 | 14.20 | 1.76 | 2.45 | 15.2 | 112 | 3.27 | 3.39 | 0.34 | 1.97 | 6.75 | 1.05 | 2.85 | 1450 |
このデータの特徴を調べるにはグラフ化するのが手っ取り早いです。
まずはアルコールAlcoholとリンゴ酸Malic.acidのデータから散布図を描き、今回の標本の特徴をみてみましょう。
[ ]:
# AlcoholとMalic.acidで散布図を描く
library(ggplot2)
g <- ggplot(data = data, aes(x=Alcohol, y=Malic.acid))
g <- g + geom_point()
g <- g + theme(text = element_text(size = 18))
g
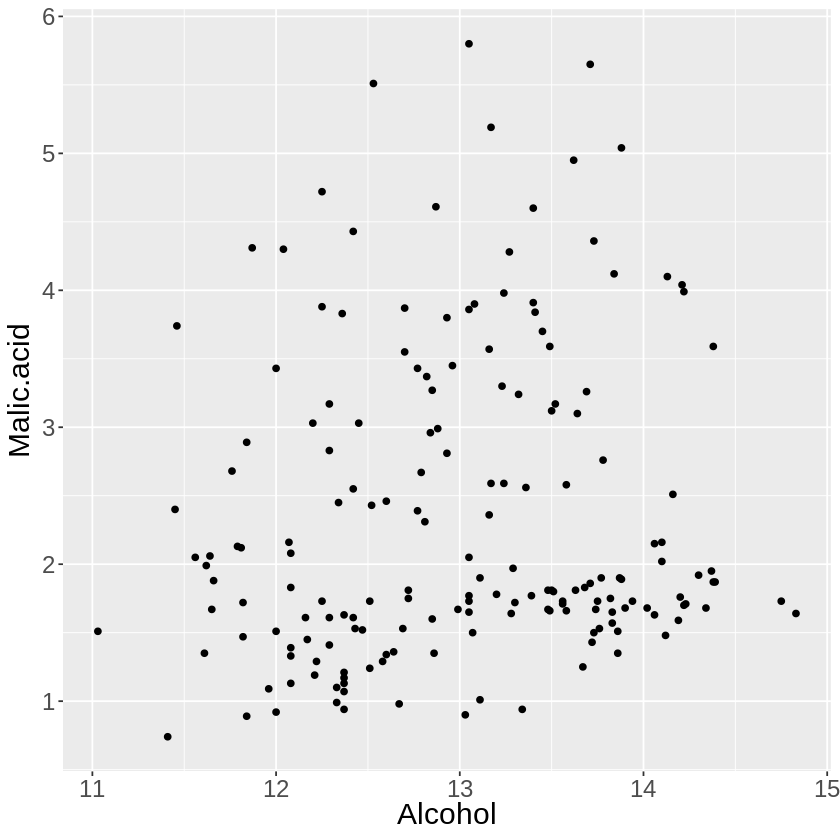
アルコールとリンゴ酸の成分では、あんまり綺麗なグループ分けは出来そうにないです。
では続いてアルコールAlcoholと灰分Ashや、総フェノールTotal.phenolsや色相Hueなど、他の成分に基づいて可視化してみましょう。
[ ]:
# AlcoholとAshなど、他の要素で散布図を描く
g <- ggplot(data = data, aes(x=Total.phenols, y=Hue))
g <- g + geom_point()
g <- g + theme(text = element_text(size = 18))
g
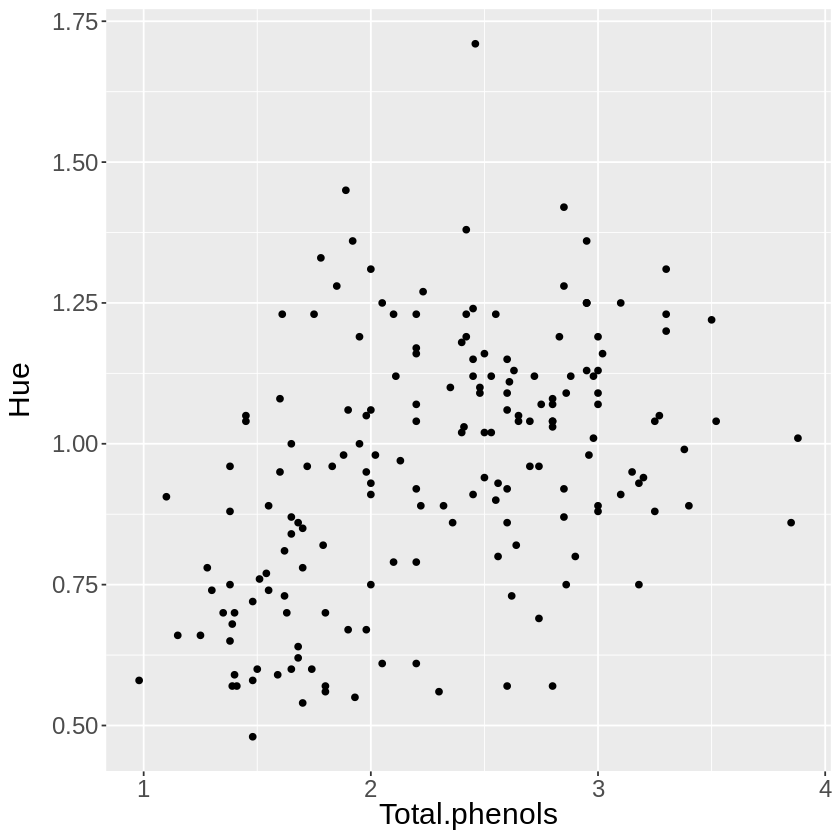
どの組み合わせでも上手くワインの種類を分けられそうにはありません。
全ての組み合わせを試すには、\(_{13}C_{2}=78\)通りのグラフを作成する必要がありますが、
なんとなく2つの成分だけでは上手くワインをグループ分け出来なさそうです。
2つの成分だけで上手くグループ分け出来ない場合は、3つ・4つ・5つ…と複数の成分を一度に考慮してグループ分け出来ないか考えたいところですが、複数の成分の情報を同時に可視化する方法が必要になります。
しかし、現状扱えるグラフ化の手法では対応できません。
この時、主成分分析を実施することで、この13個の変数の情報を出来るだけ少ない数の変数で説明していく事が出来ます。
今回の場合だと13種類の成分の情報を少ない変数で同時にある程度考慮できる形になります。

10.3.1. Rでの主成分分析の実施
まずはイメージをつかむために、実際に主成分分析をRで実施してみます。
Rでは主成分分析をprcomp関数で実施する事が出来ます。
# prcomp関数で主成分分析
rpca <- prcomp(x=データフレーム, scale=TRUE)
# 変換された変数(主成分)を表示
rpca$x
[ ]:
# prcomp関数でPCAを実施する
rpca <- prcomp(x=data, scale=TRUE)
rpca$x
| PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 | PC8 | PC9 | PC10 | PC11 | PC12 | PC13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -3.3074210 | -1.43940225 | -0.16527283 | -0.21502463 | -0.6910933491 | -0.22325037 | 0.59474883 | 0.06495586 | -0.63963836 | -1.01808396 | 0.45029317 | -0.5392891439 | 0.066052305 |
| -2.2032498 | 0.33245507 | -2.02075706 | -0.29053874 | 0.2569298662 | -0.92451231 | 0.05362434 | 1.02153432 | 0.30797798 | -0.15925214 | 0.14225602 | -0.3871456499 | -0.003626273 |
| -2.5096607 | -1.02825072 | 0.98005406 | 0.72286320 | 0.2503269758 | 0.54773096 | 0.42301218 | -0.34324787 | 1.17452129 | -0.11304198 | 0.28586645 | -0.0005819316 | -0.021655423 |
| -3.7464972 | -2.74861839 | -0.17569622 | 0.56638560 | 0.3109643979 | 0.11410911 | -0.38225899 | 0.64178311 | -0.05239662 | -0.23873915 | -0.75744764 | 0.2413387757 | 0.368444194 |
| -1.0060705 | -0.86738404 | 2.02098726 | -0.40861314 | -0.2976179585 | -0.40537608 | 0.44282531 | 0.41552831 | -0.32589984 | 0.07814604 | 0.52446563 | 0.2160546934 | 0.079140320 |
| -3.0416737 | -2.11643092 | -0.62762537 | -0.51418703 | 0.6302408998 | 0.12308335 | 0.40052393 | 0.39378261 | 0.15171810 | 0.10170891 | -0.40444443 | 0.3783653606 | -0.144747017 |
| -2.4422005 | -1.17154534 | -0.97434638 | -0.06564533 | 1.0248708712 | -0.61837638 | 0.05274195 | -0.37088763 | 0.45573029 | -1.01370392 | 0.44118887 | -0.1408325723 | 0.271013687 |
| -2.0536438 | -1.60443714 | 0.14587040 | -1.18925327 | -0.0766871685 | -1.43575612 | 0.03228452 | 0.23232360 | -0.12302328 | -0.73353084 | -0.29272910 | -0.3785950548 | 0.109853902 |
| -2.5038113 | -0.91548847 | -1.76598739 | 0.05611208 | 0.8897471068 | -0.12881767 | 0.12493265 | -0.49817262 | -0.60488290 | -0.17361686 | 0.50750129 | 0.6334624142 | -0.141683863 |
| -2.7458824 | -0.78721703 | -0.98147886 | 0.34839878 | 0.4672350615 | 0.16293204 | -0.87189274 | 0.15015593 | -0.22984080 | -0.17891540 | -0.01244307 | -0.5487787841 | 0.042335430 |
| -3.4699484 | -1.29866985 | -0.42154609 | 0.02676626 | 0.3374229486 | -0.18238714 | 0.24746432 | -1.20321684 | 0.52309838 | 0.21393410 | -0.73045409 | 0.0810835397 | -0.122257108 |
| -1.7498169 | -0.61025577 | -1.18752844 | -0.88766035 | 0.7364950947 | -0.55149954 | -0.43304467 | -0.98235543 | 0.47269706 | -0.21966314 | -0.04131960 | 0.1621036320 | -0.142368192 |
| -2.1075173 | -0.67380561 | -0.86265298 | -0.35543537 | 1.2065252604 | -0.21447112 | -0.24191476 | -0.46020817 | 0.87634134 | 0.09623390 | -0.05389442 | 0.0894940572 | 0.004921359 |
| -3.4484292 | -1.12744948 | -1.20088879 | 0.16200108 | 2.0174358634 | 0.74368299 | 1.47162215 | -0.37931575 | 0.02562985 | 0.24396442 | 1.22833591 | 0.7701609592 | -0.225186084 |
| -4.3006523 | -2.09007971 | -1.26035744 | 0.30491307 | 1.0267961441 | 0.79340481 | 0.99715808 | -0.40375247 | 0.83797870 | 0.36340778 | 0.31485795 | 0.1424179875 | 0.094457503 |
| -2.2987038 | -1.65787506 | 0.21728967 | -1.43653773 | 0.4682292849 | -0.42102574 | -0.18045845 | 0.08388008 | 0.40332020 | 0.79740574 | -0.10239527 | -0.4963955913 | 0.065814111 |
| -2.1658457 | -2.32075875 | 0.82939026 | -0.91003418 | 0.0001146171 | -0.06634216 | 0.10917980 | -0.39831121 | -0.06088354 | -0.01945896 | -0.07814600 | 0.4993884917 | -0.337151717 |
| -1.8936295 | -1.62677993 | 0.79267774 | -1.07933571 | 0.4374711602 | 0.36390428 | 0.09138877 | 0.11252284 | -0.38095864 | 0.40019204 | -0.30821248 | 0.2630832313 | -0.557720257 |
| -3.5320217 | -2.51125971 | -0.48409294 | -0.90776212 | 1.1498357895 | 0.30302223 | -0.03337008 | -0.03549998 | 0.44032391 | 0.78237000 | -0.91592459 | -0.1646236981 | -0.513095770 |
| -2.0786586 | -1.05815307 | -0.16428326 | 0.48363315 | -0.8800288984 | -1.38909922 | -0.10218393 | 0.57828400 | -0.05858753 | 0.14962722 | 0.83337570 | -0.2870648311 | -0.058544167 |
| -3.1156138 | -0.78468361 | -0.36386068 | -0.02548979 | -0.9696782562 | -0.10662100 | 0.26401773 | 0.18507933 | -1.31475355 | -0.36107268 | 0.45992273 | -0.4721266869 | 0.027701209 |
| -1.0835136 | -0.24106354 | 0.93432598 | 1.02701276 | -0.3150828842 | -1.20760838 | 0.29609645 | -0.10615184 | 0.57108824 | 0.09217260 | 0.65697654 | -0.6807690081 | 0.303788047 |
| -2.5280926 | 0.09158228 | -0.31105521 | -0.04825511 | 0.4283731687 | -1.01208813 | -0.12741024 | -0.07639854 | -0.10795820 | -0.82319600 | 0.08883189 | -0.4807458595 | 0.044807342 |
| -1.6403611 | 0.51482667 | 0.14348035 | -0.41255625 | 0.3746630851 | -0.78229875 | -0.66652200 | 0.19471617 | 0.69045467 | -0.47035563 | 0.03241438 | -0.4824855764 | 0.342783088 |
| -1.7566207 | 0.31625681 | 0.88778132 | -0.11479180 | 0.5551025444 | -0.89622074 | -0.62179685 | -0.34131105 | -0.09471675 | -0.66455568 | 0.37844150 | -0.3131924251 | 0.226906559 |
| -0.9872941 | -0.93802129 | 3.81016000 | -1.31784372 | -0.1585574371 | -0.26438245 | 0.48055175 | 0.09462456 | -0.11008285 | -0.46464800 | 0.43827492 | 0.1092096192 | 0.057938048 |
| -1.7702839 | -0.68424496 | -0.08645652 | -0.23225163 | 1.1397276528 | -0.56986696 | -0.45673986 | 0.90616486 | 0.74017507 | -0.44129910 | 0.03300611 | 0.2082476543 | -0.002159407 |
| -1.2319488 | 0.08955442 | -1.38299528 | -0.49428839 | 0.3748838960 | -0.60637766 | -0.36198918 | -0.23582299 | 0.73272686 | -0.29858956 | -0.86342413 | 0.3761562954 | -0.008567548 |
| -2.1822505 | -0.68762990 | 1.39064404 | -0.77530477 | 0.8083039404 | -0.60037885 | 0.11760101 | -0.07458529 | -0.45845040 | 0.02802756 | 0.53533708 | -0.0494390152 | 0.198140209 |
| -2.2497627 | -0.19092336 | -1.08958367 | 0.28534737 | 0.4817143982 | -0.33429055 | -0.15790489 | -0.46874203 | -0.13711523 | -0.80010223 | 0.12157357 | -0.1353494010 | 0.445353113 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 2.799168 | -1.5661160 | -0.47119874 | 0.62559373 | 0.2594411 | 0.55168667 | -0.448199854 | 0.1225273431 | -0.044501504 | -0.021806546 | -0.178231673 | 0.158062987 | 0.235003041 |
| 2.891503 | -2.0353156 | -0.49456470 | 0.46983028 | -1.4348297 | 0.17804118 | -0.392412911 | 0.0459290944 | -0.090222862 | 0.608809654 | 0.076363909 | -0.351868000 | -0.748213898 |
| 2.314209 | -2.3497377 | 0.43645057 | -0.05211277 | -2.2281419 | 0.07656257 | -1.269856586 | -0.4651562766 | -0.303792459 | 0.421752139 | 0.581149246 | 0.176744831 | -0.737942975 |
| 2.542658 | -2.0395298 | -0.31138961 | 0.38588315 | -1.8423256 | 0.97727238 | -1.622614463 | 0.2689047015 | 0.147386440 | 0.431438044 | 0.412622901 | -0.590800397 | -0.463270367 |
| 1.807443 | -1.5233488 | 1.35875689 | -0.18886315 | -1.7444663 | 0.96756214 | -1.537513656 | -0.0792671108 | -0.367737047 | 0.302216231 | 0.457901037 | 0.998859154 | 0.222630110 |
| 2.752381 | -2.1329156 | -0.96191524 | 0.66650598 | 0.4756998 | 1.79704420 | 1.015541341 | 0.3707133804 | 0.013269081 | -0.095709212 | 0.120970961 | -0.442611189 | 0.057022537 |
| 2.729451 | -0.4087333 | -1.18705614 | -0.66118009 | -0.4577455 | 1.87659660 | 0.023272553 | 0.3920897488 | 0.002283067 | -0.835469289 | -0.358689211 | 0.012170832 | -0.086390287 |
| 3.594729 | -1.7973142 | -0.09377234 | 1.26527129 | 0.6077509 | 0.19139290 | 1.414432823 | -0.1973187306 | 0.174172452 | 0.186066340 | -0.577715487 | 0.003610022 | 0.008642083 |
| 2.881697 | -1.9198031 | -0.78012193 | 1.32099902 | 0.5696361 | 0.42939440 | 0.217242924 | -0.1366167888 | -0.348358840 | 0.144780344 | 0.659578728 | -0.042367736 | 0.176074256 |
| 3.382614 | -1.3081862 | 1.59751956 | -0.48148394 | 0.6689843 | 0.80130510 | 0.095566933 | 0.1074640402 | 0.429101991 | -0.309517272 | -1.315534687 | -0.020714454 | 0.215383357 |
| 1.045233 | -3.5052019 | 1.15677544 | 0.93269836 | 0.8969184 | 3.27504281 | -0.640656143 | -0.5208667777 | -0.940613550 | -0.350894491 | 0.281045874 | -0.088014419 | 0.812886569 |
| 1.605384 | -2.3998684 | 0.54701663 | 0.75218785 | 0.9924074 | 2.91126473 | -0.709055952 | 0.1371407948 | -0.189015671 | -0.079722214 | 0.365731236 | -0.085497835 | 0.810275532 |
| 3.134290 | -0.7360846 | -0.09074275 | 0.97788934 | 0.4086607 | 0.39780019 | -0.073822979 | 1.0901152493 | 0.155359572 | 0.619307520 | -0.465989786 | 0.112859500 | 0.317937601 |
| 2.233855 | -1.1721588 | -0.10109176 | -1.16200085 | 0.2637054 | -0.79878548 | 0.538364032 | -0.1322312343 | -0.554027438 | 0.246126740 | 0.221436973 | 0.101839510 | 0.437275935 |
| 2.839663 | -0.5544798 | 0.80195300 | -0.89536236 | 0.2540846 | -0.28775631 | 0.865321429 | 0.2512752825 | -0.317714358 | -0.251911642 | -0.006822216 | -0.315748794 | 0.228603203 |
| 2.590190 | -0.6960022 | -0.88245023 | -0.27345736 | -0.7700632 | -0.71781755 | 0.271733724 | 0.2598086664 | 0.338537132 | -0.224169920 | 0.212061213 | 0.168327300 | -0.057330493 |
| 2.941003 | -1.5509340 | -0.98063447 | 0.01543680 | 0.3630580 | 0.48982426 | -0.983161709 | -0.7835869145 | -0.355326136 | -0.007632986 | 0.073483354 | -0.476401026 | -0.100991274 |
| 3.520102 | -0.8800443 | -0.46471821 | 0.57915590 | 0.6670780 | -0.45752369 | 0.520751690 | -1.0721033406 | -0.485071111 | -0.034180228 | 0.006251150 | -0.120136436 | -0.080859845 |
| 2.399342 | -2.5850640 | 0.42702163 | -0.18381657 | -0.4464019 | 0.56790428 | 0.035701360 | -0.6713512455 | -0.167534421 | 0.863419750 | 0.097170993 | -0.797403434 | 0.090238691 |
| 2.920845 | -1.2708620 | -1.20994516 | 0.29448534 | 0.2665979 | 0.38014078 | -0.642508297 | 0.0005513564 | 0.501117492 | 0.598336500 | -0.075425553 | -1.076619204 | 0.112673491 |
| 2.175277 | -2.0716933 | 0.76163407 | -0.38849742 | -0.3588613 | 0.62779685 | -0.751203293 | -0.9234686974 | 0.109524582 | -0.216024966 | 0.224580421 | -0.152651832 | 0.148077986 |
| 2.374230 | -2.5813857 | 1.41405515 | 0.58684651 | -1.1248238 | -0.98087803 | -0.927855274 | -0.2931778502 | 0.002518568 | 0.706795796 | 0.151962189 | -0.250894583 | 0.394913655 |
| 3.202583 | 0.2505424 | -0.84474622 | -0.21645476 | -0.6073819 | -0.39426556 | -0.291028344 | 0.5812665877 | 0.595443562 | -0.154489700 | 0.198615485 | -0.244754483 | 0.023830564 |
| 3.667573 | -0.8453632 | -1.33565252 | -0.12482375 | 0.4847445 | 0.85554582 | -1.022754949 | 0.6741852287 | -0.020565244 | 0.027260064 | 0.128627190 | -0.802328358 | -0.025895627 |
| 2.458620 | -2.1876273 | -0.91619648 | 0.01797429 | 0.6992371 | 0.67893979 | -0.826866628 | -0.2956820474 | -0.325916860 | -0.273387535 | 0.607010545 | -0.098363306 | 0.258469201 |
| 3.361043 | -2.2100548 | -0.34160588 | 1.05554926 | 0.5725488 | -1.10566946 | 0.955719862 | -0.1456865033 | 0.022434370 | 0.303261896 | -0.138836000 | -0.170305498 | 0.114104734 |
| 2.594637 | -1.7522864 | 0.20699744 | 0.34851331 | -0.2543457 | -0.02639093 | 0.146480343 | -0.5508730937 | 0.097693793 | 0.205481149 | -0.257471452 | 0.278645029 | 0.186844213 |
| 2.670307 | -2.7531329 | -0.93829506 | 0.31115701 | -1.2677788 | 0.27229980 | 0.677324754 | 0.0468915289 | -0.001218709 | 0.247299709 | -0.511050413 | -0.696800860 | -0.071874944 |
| 2.380303 | -2.2908844 | -0.54914712 | -0.68634844 | -0.8116656 | 1.17546713 | 0.632191933 | 0.3897293942 | -0.057286075 | -0.490106969 | -0.298978585 | -0.338864757 | 0.021804253 |
| 3.199732 | -2.7611307 | 1.01106158 | 0.59522413 | 0.8926745 | 0.29525929 | 0.005725107 | -0.2920897840 | -0.739574173 | 0.117637179 | 0.229317454 | 0.188256913 | 0.323053425 |
主成分分析を実施することで、新しくPC1 ~ PC13の変数(第1主成分~第13主成分)が計算されました。
(※PC1 = Principle Component 1 (第1主成分)の略です)
それぞれの主成分(PC1~PC13)でどのくらいの情報を捉えているかは、summary関数で確認できます。
各主成分の捉えた分散の割合を表示
summary(rpca)
[ ]:
# 各主成分の説明する割合を表示
summary(rpca)
Importance of components:
PC1 PC2 PC3 PC4 PC5 PC6 PC7
Standard deviation 2.169 1.5802 1.2025 0.95863 0.92370 0.80103 0.74231
Proportion of Variance 0.362 0.1921 0.1112 0.07069 0.06563 0.04936 0.04239
Cumulative Proportion 0.362 0.5541 0.6653 0.73599 0.80162 0.85098 0.89337
PC8 PC9 PC10 PC11 PC12 PC13
Standard deviation 0.59034 0.53748 0.5009 0.47517 0.41082 0.32152
Proportion of Variance 0.02681 0.02222 0.0193 0.01737 0.01298 0.00795
Cumulative Proportion 0.92018 0.94240 0.9617 0.97907 0.99205 1.00000
Proportion of Varianceが13個の変数によって生じていた分散全体の何%の情報を捉えているかを表しています。
具体的には、主成分分析によって、13個の変数の情報を捉えた変数として、
36.2%を説明する変数(第1主成分, PC1)
19.2%を説明する変数(第2主成分, PC2)
11.1%を説明する変数(第3主成分, PC3)
…
と、情報の大部分を説明できる変数ができたことになります。
biplot関数を適用することで、第1主成分と第2主成分から成る散布図と、
各主成分が元のどの変数とどれだけ強い相関を持っているかを示す因子負荷量を図示できます。
biplot(prcompの結果)
[ ]:
# biplot関数で第1主成分・第2主成分で散布図+因子負荷量を描く
biplot(rpca)

第1主成分はデータ全体の36.2%、第2主成分は19.2%を説明しているので、データの56%の情報に基づいた散布図、と言えます。
因子負荷量を見てみると、例えば
第2主成分(y軸)が低いワインはAshやAlcohol, Color.intensityが高い傾向にある
第1主成分(x軸)が高いワインはAlcalicity.of.ashやNonflavanoid.phenolなどが高い傾向にある
といったことが分かります。13変数を総合的に見てワインを位置付けている形です。
勿論第1,2主成分だけだとデータの56%の情報だけになりますが、最初に実施したAshとMalic.acidの2変数の散布図に比べると、より多くの情報に基づいた可視化と言えます。
また、2変数だけではワインの分類が出来ませんでしたが、
この第1主成分と第2主成分の散布図を見ると、ワインの種類は3つくらいのグループに分類できそうだということが分かります。
第2主成分が高いグループ
第1主成分が高く、第2主成分が低いグループ
第1主成分が低く、第2主成分が低いグループ

実際に、このデータは3種のぶどう品種いずれかから作られた178種類のワインのデータであり、
大きくワインをグループ分けすると、ぶどう品種に基づいて3グループに分かれる、というのは十分あり得そうです。
(元データ: https://archive.ics.uci.edu/dataset/109/wine)
次のコードでぶどうの品種classも含めたデータが読み込めるので、成分(の56%の情報)に基づいて分けた3グループと、実際の元となったブドウ品種がどれだけ対応しているか確認してみます。
[ ]:
# ぶどう品種データも含めたデータセットの読み込み
data <- read.csv("https://raw.githubusercontent.com/slt666666/biostatistics_text_wed/refs/heads/main/source/_static/data/chapter10_wine.csv")
head(data)
| class | Alcohol | Malic.acid | Ash | Alcalinity.of.ash | Magnesium | Total.phenols | Flavanoids | Nonflavanoid.phenols | Proanthocyanins | Color.intensity | Hue | OD.diluted.wines | Proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <int> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <int> | |
| 1 | A | 14.23 | 1.71 | 2.43 | 15.6 | 127 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065 |
| 2 | A | 13.20 | 1.78 | 2.14 | 11.2 | 100 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050 |
| 3 | A | 13.16 | 2.36 | 2.67 | 18.6 | 101 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185 |
| 4 | A | 14.37 | 1.95 | 2.50 | 16.8 | 113 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480 |
| 5 | A | 13.24 | 2.59 | 2.87 | 21.0 | 118 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735 |
| 6 | A | 14.20 | 1.76 | 2.45 | 15.2 | 112 | 3.27 | 3.39 | 0.34 | 1.97 | 6.75 | 1.05 | 2.85 | 1450 |
PCAを実施して得られる第1主成分と第2主成分の散布図に、ぶどうの品種で色付けしてみると
[ ]:
library(ggplot2)
# 13成分のデータからPCAを実施
rpca <- prcomp(x=data[,2:14], scale=TRUE)
# 第1主成分と第2主成分をデータフレームに追加
data$PC1 <- rpca$x[,1]
data$PC2 <- rpca$x[,2]
# PC1とPC2の散布図をぶどう品種で色分けして描写
g <- ggplot(data = data, aes(x=PC1, y=PC2))
g <- g + geom_point(aes(colour=class))
g

主成分分析によって、ワインの13種の成分の情報を少ない変数で総合的に捉えて可視化した結果、
成分に基づいて分けられた3つのグループが、ぶどう品種由来のものだと確認できます。
この様に、主成分分析を用いることで、多数の変数から成るデータの特徴を少ない変数で可視化する事が出来ます。
10.3.2. 活用例
生物学において主成分分析が活躍する場面の1つとして、遺伝子型情報の解析があります。
例えば下のコードで読み込めるデータは、様々な土地でメヒシバという植物を19サンプル採集し、各サンプルのゲノム配列を解読して得られたゲノム配列の違いを示した結果になります。
ゲノム上の各位置において、各サンプル毎に変異が入っていれば2, 入っていなければ0, ヘテロの場合は1となっています。
[ ]:
# 遺伝子型情報の例を読み込む
data <- read.csv("https://raw.githubusercontent.com/slt666666/biostatistics_text_wed/refs/heads/main/source/_static/data/chapter10_genetic_variants.csv")
head(data)
| sample | chr01_92350 | chr01_1674237 | chr01_1845787 | chr01_2771057 | chr01_3083332 | chr01_4916097 | chr01_4936298 | chr01_5536949 | chr01_5849537 | ⋯ | chr09_54951418 | chr09_55858506 | chr09_56682602 | chr09_56793541 | chr09_57199744 | chr09_57364173 | chr09_60669105 | chr09_62120010 | chr09_62561363 | chr09_65022563 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <int> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <int> | ⋯ | <dbl> | <dbl> | <int> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| 1 | sample1 | 0 | 2 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | ⋯ | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
| 2 | sample2 | 0 | 2 | 0 | 2 | 0 | 2 | 0 | 0 | 0 | ⋯ | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
| 3 | sample3 | 0 | 2 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | ⋯ | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 4 | sample4 | 0 | 2 | 0 | 2 | 0 | 2 | 0 | 0 | 0 | ⋯ | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
| 5 | sample5 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 0 | ⋯ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
| 6 | sample6 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 0 | ⋯ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
この情報に基づいて、19サンプルをゲノム配列が近いものでグループ分けしたいとします。
505箇所のゲノム上の変異の情報をそのまま扱おうとすると大変ですが、主成分分析で全体の情報を要約した変数にまとめていくことで、全ての情報を扱う事が出来ます。
1列目はサンプル名なので、2列目以降のデータdata[,2:506]を使用してPCAを実施してみましょう。
# prcomp関数で主成分分析
rpca <- prcomp(x=データフレーム, scale=TRUE)
# 各主成分の捉えた分散の割合を表示
summary(rpca)
[ ]:
# ゲノム情報に対しPCAを実施
rpca <- prcomp(x=data[,2:506], scale=TRUE)
summary(rpca)
Importance of components:
PC1 PC2 PC3 PC4 PC5 PC6 PC7
Standard deviation 16.1591 5.3605 5.00036 4.77797 4.73191 4.54865 4.40400
Proportion of Variance 0.5171 0.0569 0.04951 0.04521 0.04434 0.04097 0.03841
Cumulative Proportion 0.5171 0.5740 0.62347 0.66868 0.71302 0.75399 0.79239
PC8 PC9 PC10 PC11 PC12 PC13 PC14
Standard deviation 4.11218 4.03600 3.89022 3.77317 2.97980 2.90458 2.64631
Proportion of Variance 0.03349 0.03226 0.02997 0.02819 0.01758 0.01671 0.01387
Cumulative Proportion 0.82588 0.85814 0.88810 0.91630 0.93388 0.95058 0.96445
PC15 PC16 PC17 PC18 PC19
Standard deviation 2.49144 2.26023 1.83220 1.81078 9.041e-15
Proportion of Variance 0.01229 0.01012 0.00665 0.00649 0.000e+00
Cumulative Proportion 0.97674 0.98686 0.99351 1.00000 1.000e+00
ゲノムデータに対し主成分分析を実施すると、第1主成分で51.7%を説明し、第2主成分で5.7%の情報を説明できることが分かります。
第1, 第2主成分で散布図を描いてみると
[ ]:
library(ggplot2)
# PC1とPC2の散布図を描写
g <- ggplot(data = rpca$x, aes(x=PC1, y=PC2))
g <- g + geom_point()
g

この様に、第1主成分が大きいグループと小さいグループに分かれ、第1主成分が小さいグループの中には、第2主成分が大きいグループと小さいグループにさらに分かれそうです。
実際、今回の19サンプルには、コメヒシバとメヒシバという2種混ざっており、これが第1主成分で綺麗に分かれています。
また、メヒシバのサンプルは、様々な地点から採集しており、環境への適応に応じたゲノム配列の変化を第2主成分が示しているのでは…?などと考察できます。

10.3.3. 主成分の計算について
ここまではRの関数で主成分分析を行ってきましたが、実際にどの様な計算が為されているかを簡単に紹介しておきます。
以下の様なデータがあるとします。
\begin{array}{ccccc} \hline 変数 & x_1 & x_2 & … & x_p \ \hline 1 & x_{11} & x_{21} & … & x_{p1} \ 2 & x_{12} & x_{22} & … & x_{p2} \ 3 & x_{13} & x_{23} & … & x_{p3} \ … & … & … & … & … & … \ n & x_{1n} & x_{2n} & … & x_{pn} \ \hline \end{array}
まず、\(x_1 \sim x_p\)の分散共分散行列\(S\)を求めます。
\(S = \begin{bmatrix} s_1^2 & s_{12} & ... & s_{1p} \\ s_{12} & s_2^2 & ... & s_{2p} \\ \vdots & & & \vdots \\ s_{1p} & s_{2p} & ... & s_p^2 \end{bmatrix}\)
※\(s_i^2\)は\(x_i\)の分散、\(s_{ij}\)は\(x_i, x_j\)の共分散
そしてこの分散共分散行列\(S\)の固有値\(\lambda\)を求めます。
固有値\(\lambda\)は下記の行列式を解くことで求められます。
\(\begin{vmatrix} s_1^2 - \lambda & s_{12} & ... & s_{1p} \\ s_{12} & s_2^2 - \lambda & ... & s_{2p} \\ \vdots & & & \vdots \\ s_{1p} & s_{2p} & ... & s_p^2 - \lambda \end{vmatrix} = 0\)
この行列式を解くと、固有値\(\lambda\)は\(p\)個の解をもち、導出された\(p\)個の固有値は、
\(\lambda_1 \ge \lambda_2 \ge \lambda_3 ... \ge \lambda_p \ge 0\)
と大きい順に並べられます。
この大きい固有値に属する固有ベクトルから、第1主成分の係数、第2主成分の係数、という順で係数が得られます。
\(\begin{bmatrix} s_1^2 & s_{12} & ... & s_{1p} \\ s_{12} & s_2^2 & ... & s_{2p} \\ \vdots & & & \vdots \\ s_{1p} & s_{2p} & ... & s_p^2 \end{bmatrix} \begin{bmatrix} a_{i1} \\ a_{i2} \\ \vdots \\ a_{ip} \end{bmatrix}=\lambda_i \begin{bmatrix} a_{i1} \\ a_{i2} \\ \vdots \\ a_{ip} \end{bmatrix}\)
※条件として\(a_{i1}^2+a_{i2}^2+\cdots+a_{ip}^2 = 1\)
最も大きい固有値\(\lambda_1\)の固有ベクトル\((a_{11}, a_{12}, a_{13}, ..., a_{1p})\)に対し、
第1主成分\(z_1 = a_{11}x_1 + a_{12}x_2 + a_{13}x_3 + \cdots + a_{1p}x_p\)と得る事が出来ます。
同じように2番目に大きい固有値\(\lambda_2\)とその固有ベクトルから第2主成分が求められ、3番目に大きい…と続けて求められます。
10.3.4. 寄与率
先ほど、第1主成分で36%を説明でき、第2主成分で19%を説明できる…という値がありました。
この何%説明できるかの値を主成分の寄与率と呼びます。
寄与率は下記の式で計算できます。
寄与率$ = :nbsphinx-math:`dfrac{lambda_i}{lambda_1 + lambda_2 + lambda_3 + cdots + lambda_p}`$
線形代数の講義を取った方は固有値とか固有ベクトルとかを学んだかと思いますが、主成分分析はその活用例の1つになります。
今回は算出方法だけ紹介したので、なぜ固有値から主成分が算出できるかは応用が見える線形代数などを参照してみてください。
もちろんRでは固有値や固有ベクトルの算出もeigen関数などを用いて実施できるので参考に載せておきます。
[ ]:
# データから固有値等を算出、各主成分の寄与率を求める
data <- read.csv("https://raw.githubusercontent.com/slt666666/biostatistics_text_wed/refs/heads/main/source/_static/data/chapter10_wine_unknown.csv")
# cov関数で分散共分散行列を計算する
scaled_data <- scale(data)
cov_matrix <- cov(scaled_data)
# 固有値・固有ベクトルをeigen関数で計算
eigen_cov_matrix <- eigen(cov_matrix)
# 最大の固有値(この固有ベクトルから第1主成分が算出できる)
# eigen_cov_matrix$values[1]
# 最大の固有値における固有ベクトル
# eigen_cov_matrix$vectors[,1]
# 第一主成分の寄与率
eigen_cov_matrix$values[1] / sum(eigen_cov_matrix$values)
10.4. クラスタリング
データをグループ分けする教師なし学習の手法としては、クラスタリングと呼ばれる手法もあります。
主成分分析では変数を要約する(少数の変数にデータをまとめる)ことで、データ全体の特徴を捉えました。
クラスタリングでは、全てのデータに基づき、サンプル同士のデータ類似度(距離)を計算して、近いものからグループを作成していきます。
クラスタリングには大きく分けて階層的クラスタリングと非階層的クラスタリングがあります。
10.4.1. 階層的クラスタリング
より直感的にイメージしやすい階層的クラスタリングの方から説明していきます。
階層的クラスタリングでは、似ている組み合わせを順番にまとめていき、樹形図(デンドログラム)を作成します。
その後、完成した樹形図をもとにデータをクラスターに分割する手法となります。
例えばデータA, B, C, D, Eがあった時に、どの様にデータをまとめていくか見ていきます。
似ているデータをまとめていく手法のイメージとしては下記の様になります。

こうして作成した樹形図(デンドログラム)に基づいて、データを任意の数のクラスターに分割します。
A, B, C, D, Eを3つのグループに分けたい場合は、下図の様に3つに分かれる位置で区切ります。

10.4.2. 類似度の計算
データをまとめて樹形図を作成する際に、まずデータの類似度を計算する必要があります。

この類似度を計算する方法には様々な手法があり、
ユークリッド距離(Euclidean)
ミンコフスキー距離(Minkowski)
マンハッタン距離(Manhattan)
…etc
等の指標が代表的なものとして扱われます。
例えばユークリッド距離はどのような計算かというと、
\(A(x_{1},y_{1})\) と \(B(x_{2},y_{2})\)の間のユークリッド距離は、差の二乗和の平方根
\(\sqrt{(x_{2}-x_{1})^{2}+(y_{2}-y_{1})^{2}}\) で計算されます。
また、点と点の間だけでなく、クラスター間の類似度を計算する方法も必要になります。

この計算には、
最短距離法(単連結法)… 2つのクラスターの間で、最も近い個体間の距離をクラスター間の距離とする
最長距離法(完全連結法)… 2つのクラスターの間で、最も遠い個体間の距離をクラスター間の距離とする
群平均法 … 全個体間の距離の平均をクラスター間の距離とする
ウォード法(最小分散法)… 併合した後のクラスター内の分散の増加が最も小さくなるペアを選ぶ
…etc
といった様々な計算手法があります。特にウォード法は良く用いられる手法になります。
10.4.3. Rでの階層的クラスタリングの実施
Rではdist関数で各データ間の距離を計算し, hclust関数で樹形図を作成する事が出来ます。
#scale()関数を使ってデータを標準化
scaled_data <- scale(data)
# dist関数で距離行列を作成、デフォルトがユークリッド距離euclidean
d <- dist(scaled_data, method = "距離の種類")
# hclust関数で樹形図を作成、デフォルトが最長距離法complete
hc <- hclust(d, method = "使用メソッド")
# 作成した樹形図を作図
plot(hc)
先ほどのワインのデータを使用して、樹形図を作成してみましょう。
[ ]:
# ワインのデータを使用して階層的クラスタリングを実施
data <- read.csv("https://raw.githubusercontent.com/slt666666/biostatistics_text_wed/refs/heads/main/source/_static/data/chapter10_wine_unknown.csv")
scaled_data <- scale(data)
d <- dist(scaled_data)
hc <- hclust(d)
plot(hc)
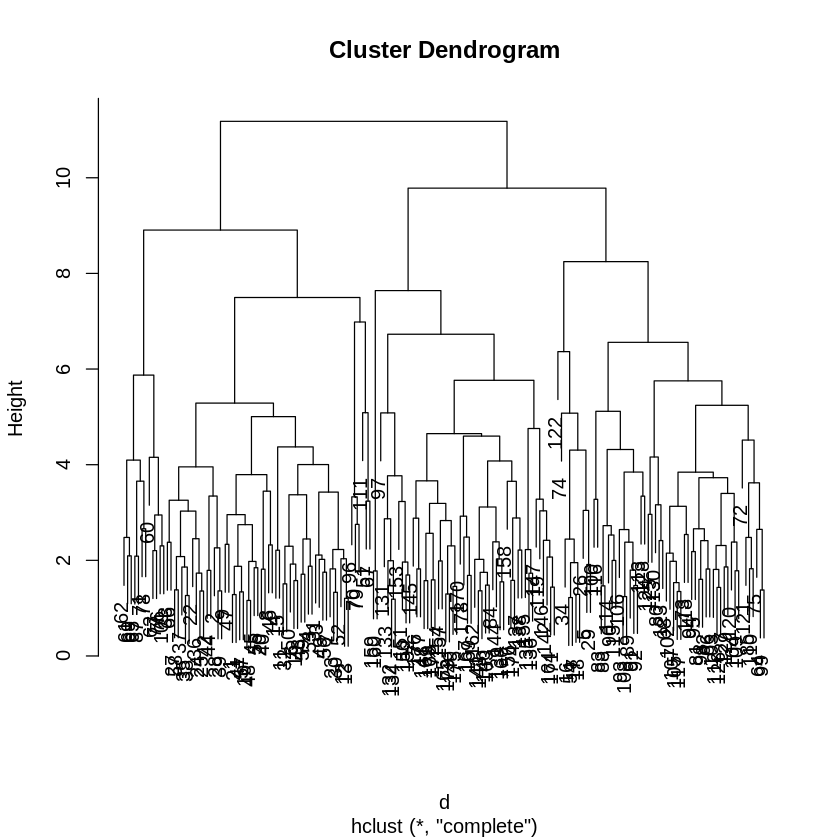
この様に、dist関数、hclust関数で178種類のワインの成分情報に基づいた樹形図を作成する事が出来ました。
このクラスタリングの結果は、cutree関数で任意の数のクラスターに分ける事が出来ます。
# 樹形図を基に任意のクラスター数に分ける
clusters <- cutree(tree, k = 分割するクラスター数)
clusters
例えば先ほどの階層的クラスタリングの結果を基に、3つのクラスターに分割すると
[ ]:
# cutree関数でクラスター分割を実施する
clusters <- cutree(hc, k=3)
clusters
- 1
- 1
- 1
- 1
- 2
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 2
- 2
- 2
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 2
- 1
- 1
- 2
- 1
- 1
- 1
- 1
- 2
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 2
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 2
- 1
- 1
- 1
- 2
- 1
- 1
- 1
- 2
- 2
- 2
- 2
- 1
- 1
- 1
- 1
- 2
- 2
- 2
- 2
- 3
- 2
- 2
- 1
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 1
- 3
- 2
- 2
- 2
- 1
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 1
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 3
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
この様な形で、何番目のデータがどのクラスターに入るか、表示してくれます。
このクラスターはワインの成分に基づいて作成されたクラスターですが、どのぶどう品種(A,B,C)由来のワインかという情報と一致するのかtable関数を用いて照らし合わせてみると…
[ ]:
# 今回のクラスター結果と実際に基になったぶどう品種の対応を確認
data <- read.csv("https://raw.githubusercontent.com/slt666666/biostatistics_text_wed/refs/heads/main/source/_static/data/chapter10_wine.csv")
table <- table(data$class, clusters)
table
clusters
1 2 3
A 51 8 0
B 18 50 3
C 0 0 48
といった形で、A,B品種の分類は少しクラスタリング結果とは異なっていますが、概ねワインの成分に基づくクラスタリング結果と材料となったぶどうの品種が一致していることが分かります。
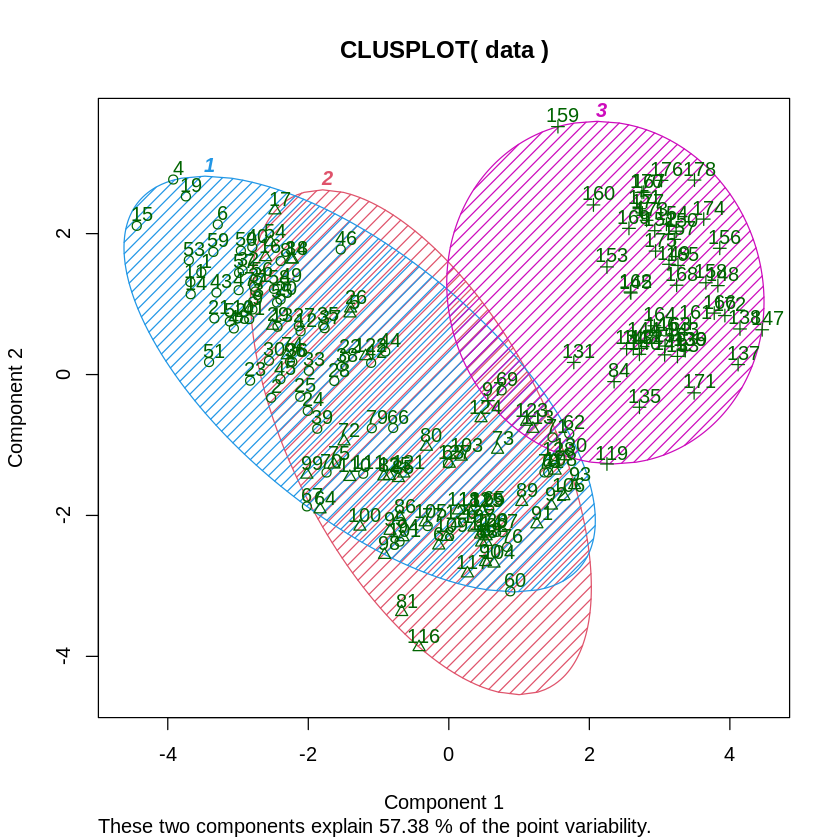
ちなみに、Rのclusterパッケージのclusplotという関数を使用すると、主成分分析に基づいた散布図に、視覚的にクラスターを描写してくれます。
[ ]:
# クラスタリング結果のプロット
library(cluster)
clusplot(data, clusters, color=TRUE, shade=TRUE, labels=2, lines=0)
10.4.4. 非階層的クラスタリング
続いて、非階層的クラスタリングを扱います。文字通り階層を作らない手法なので、先ほどの樹形図の様なものは作成せずに、データを直接任意の数のクラスターに分割する方法になります。
今回はk-means法という非階層的クラスタリングの代表的な手法を扱います。
この手法を用いて、データを3つのクラスターに分割する場合、以下の様な計算が行われます。

実際の計算としては、各クラスター内での変動が最小になる様な分割方法を求めていくことになります。
先ほど紹介したユークリッド距離を使用した場合、クラスター内の変動は下式によって定義されます。
\(W(C_k) = \dfrac{1}{|C_k|}\sum_{i,i'\in C_k}\sum_{j=1}^p(x_{ij}-x_{i'j})^2\)
各クラスターに属するデータ点から、重心への距離の2乗の合計です。
このクラスター内の変動を全てのクラスターで足し合わせた、総クラスター内変動が出来る限り小さくなる様にK個のクラスターに分割します。
\(minimize\{{\sum_{k=1}^K W(C_K)}\}\)
これを解くのは最適化問題と呼ばれる問題で中々難しいので、今回はRの関数に頼ります。
(※最適化問題自体は面白い分野なので興味があれば調べてみてください。)
10.4.5. Rによる非階層的クラスタリングの実施
Rのkmeans関数を使用することで、k-means法を用いた非階層的クラスタリングを実施する事が出来ます。
kmeans関数は下記の様に使用します。
#scale()関数を使ってデータを標準化
scaled_data <- scale(data)
# kmeans関数でクラスタリングを実施
km <- kmeans(scaled_data, centers=クラスターの数)
# クラスターの分類結果を表示
km$cluster
ワインのデータを使用して、非階層的クラスタリングを実施してみましょう。
[ ]:
# ワインのデータを使用して非階層的クラスタリングを実施
data <- read.csv("https://raw.githubusercontent.com/slt666666/biostatistics_text_wed/refs/heads/main/source/_static/data/chapter10_wine_unknown.csv")
scaled_data <- scale(data)
km <- kmeans(scaled_data, centers=3)
km$cluster
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 2
- 1
- 1
- 3
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 2
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 3
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 2
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 3
- 1
- 1
- 2
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 1
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
- 3
データが1~3に分割されていることが分かります。
こちらも先ほどと同様にぶどう品種との対応や、クラスター結果の可視化が出来ます。
[ ]:
# 今回のクラスター結果と実際に基になったぶどう品種の対応を確認
data <- read.csv("https://raw.githubusercontent.com/slt666666/biostatistics_text_wed/refs/heads/main/source/_static/data/chapter10_wine.csv")
table <- table(data$class, km$cluster)
table
# クラスター結果の描写
library(cluster)
clusplot(data, km$cluster, color=TRUE, shade=TRUE, labels=2, lines=0)
1 2 3
A 0 59 0
B 65 3 3
C 0 0 48
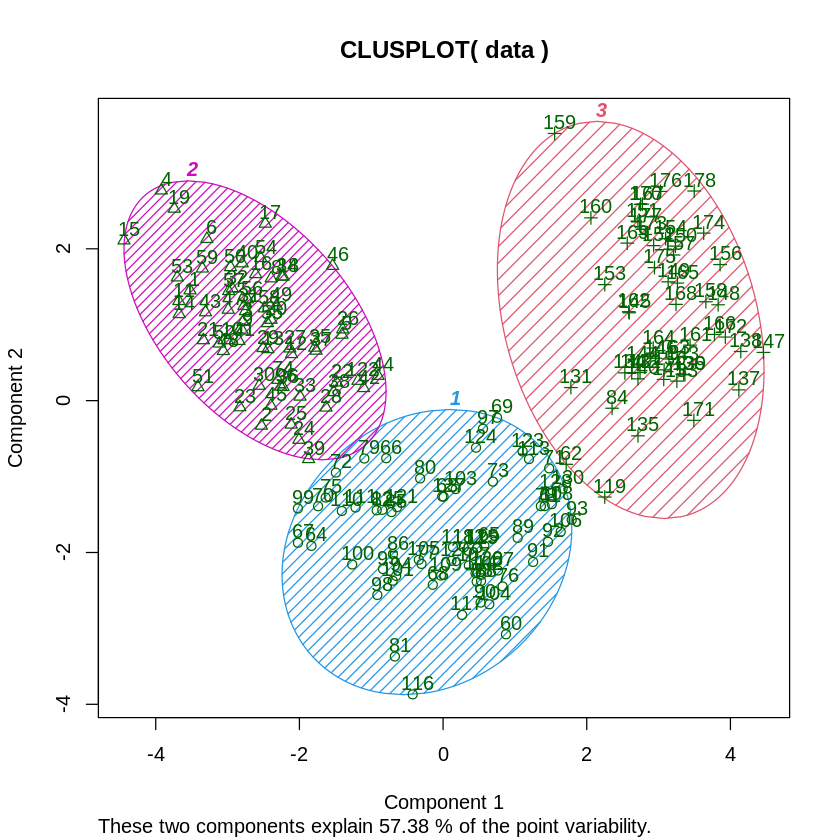
階層的クラスタリングの時よりもよりぶどう品種ごとの分類と一致したクラスタリング結果となりました。
※ただし、ワイン製造過程の方法などが影響を与えている場合もあるので、品種と一致しているクラスタリング結果が正しいというわけではありません。
この様な形で、データセット全体の情報を要約した主成分を作成したり、クラスタリングによってデータを分類することが出来ます。
必ず意味のあるグループに分類されるとは限りませんが、大まかに分けるとどの様な特徴を持つデータがあるのかを確認する際には、強力な手法となります。
10.4.6. 活用例
特に生物学においては、遺伝子の発現情報に対してクラスタリングを適用する場合が多いです。
生物は数千~数万の単位の遺伝子がゲノム情報にコードされており、その全てが発現量という情報を持ちます。
その中で発現量が上昇している遺伝子グループはどのくらいの数あるのか、といった情報をクラスタリングによって確認する事が出来ます。
下図は水または病原菌を接種したイネの遺伝子発現量を表しています。
左3列が水、右3列が病原菌を接種した結果になっており、各行が各遺伝子の発現量を表しています。
階層的なクラスタリングが行われており、」水では発現量が低いが病原菌では発現量が高くなった遺伝子のグループ」の様なクラスターを確認できます。
