5. 第5回 標本分布
![]()
5.1. はじめに
統計学では、ある集団の特徴を知りたいときに、集団全体のデータからではなく、一部のデータから特徴を推測することが多いです。
例えば「京都府の中に、京都大学を卒業した人がどのくらいの割合いるのか」を知りたい時に、京都府民全員の学歴を調査するのは途方もない労力がかかります。 そこで、例えば京都府民から100人ランダムに選んで調査した結果から目的の割合を推測する、といった形です。
これは実験に関しても同様で、「ある植物に物質Aを与えた効果」を調べる際に、複数回実験を行って効果を調べることが多いかと思います。 これも、本来無限回実験を繰り返して効果を確認するところを、得られた複数回のデータから実際の効果を推測する、ということを実施している形になります。
これまで、手元にあるデータの特徴を捉えるための記述統計学や可視化の方法について学んできましたが、 今回は、この手元にあるデータから、元となっている集団の特徴を推測する、という数理統計学の基礎となる考え方を学んでいきます。
5.2. 母集団と標本

これから特徴等を知りたい集団全体のことを母集団と呼びます。
さきほども説明した通り、この母集団について直接知ることは難しいことが多いです。
母集団の要素が非常に大きい。(調査対象が国民全体、実験の例のように対象が無限大の場合も。)
予算などの制約により、調査できる数に限りがある。
といったことが主な理由となります。(ちなみに集団全体を調査する場合を全数調査と呼ぶ。)
この場合、母集団から一部を抽出し、部分的な集団を分析することで、母集団について推測を行うことになります。
母集団から抽出することを標本抽出:sampling、抽出されたものを標本:sampleと呼びます。
統計的推測においては、抽出した標本から母集団の特徴(例えばある地域に生息する植物の草丈の特徴など)を知ることが目標となりますが、
より具体的にいうと、母集団の従う分布を知ることが目的となります。

母集団が上図の様な分布に従っている場合、この集団から一部を標本として抽出することで、元の分布を推測する形です。
そのため、統計的推測について学ぶためには分布とはいったい何なのか、
つまり、確率分布の概念や確率変数について知っておく必要があります。
そこで、まずは確率変数や確率分布について学習します。
5.3. 確率変数と確率分布
確率とは、事象の起こりやすさを定量的に示したものになります。事象Aの起きる確率を\(P(A)\)と表します。
たとえば、宝くじに当たるという事象が起きる確率は2000万分の1なので、\(P(宝くじに当たる) = 1/20000000\)という形になります。
ここで、ある島に生息するシロツメクサの葉の長さを調査することを想定します。
島に生息するシロツメクサ全個体が母集団となり、採集した個体が標本になります。
ここで、採集した個体の葉の長さ\(X\)は、さまざまな値をとる変数です。
この\(X\)の値は、ランダムな値をとるのではなく、母集団における\(X\)の分布をある程度反映することが想定されます。
(7cmの個体が島に多く生息していれば、採集個体も7cmの長さが多くなる)

つまり、7㎝の個体が採集される事象は、母集団に7cmの個体が含まれる割合に依存して出現します。
このように、とりうる各値に対し、それぞれ確率が与えられている様な変数を確率変数と呼びます。
また、各値が観察される確率の分布を確率分布と呼びます。
他の例でいうと、サイコロを振って出る目\(X\)も確率変数です。\(X\)は1から6までの数字を取り、各数字が生じる確率は1/6になります。
\(P(X=1)=1/6, P(X=2)=1/6, ... , P(X=6)=1/6\)
ここで、サイコロの目\(X\)は1,2,3,4,5,6と、取りうる値が6種類に決まっていますが、シロイヌナズナの葉の長さは連続的な値をとります。

サイコロのような、取りうる値が可算集合(数え上げることができる集合)の値をとる確率変数\(X\)は離散型の確率変数と呼び、
葉の長さの様な取りうる値が連続的な確率変数\(X\)は連続型の確率変数と呼びます。
離散型の確率変数\(X\)の場合、それぞれの値の確率は、
\(P(X=x_k) = f(x_k)\) \((k=1,2,...)\) と表され、確率分布\(f\)は
\(f(x_k) \geqq 0\) かつ \(\sum_{k=1}^\infty f(x_k)=1\) の条件を満たします。
サイコロの場合、\(x_1 = 1, x_2 = 2, ... x_6 = 6\)で、\(f(x_k) = 1/6\)ということになります。

連続型の確率変数\(X\)の場合、確率は
\(P(a \leqq X \leqq b) = \int_{a}^{b} f(x)dx\) と表され、\(f(x)\)は確率密度関数と呼び、
\(f(x) \geqq 0\) かつ \(\int_{-\infty}^\infty f(x)dx=1\)
の条件を満たします。
5.3.1. 確率変数の期待値と分散
5.3.2. 期待値
確率変数は様々な値をとりますが、それらの値を代表する平均値が期待値となります。
宝くじを例にすると、1/20000000の確率で1億円があたり、それ以外は100円があたる宝くじがあったとします。
これは、
\(P(X = 100000000) = 1/20000000\)
\(P(X = 100) = 19999999/20000000\)
と表されるので、この時この宝くじで得られるであろう金額は、
\(100000000 \times 1/20000000 + 100 \times 19999999/20000000\)と、得られる金額 x その金額が起きる確率の和で計算できます。
[ ]:
# 宝くじの期待値の計算
100000000*1/20000000+100*19999999/20000000
このような、確率変数\(X\)に対して、それがとる値の重み付き平均を確率変数\(X\)の期待値といい\(E(X)\)と書きます。
\(E(X)\)は、
離散型の場合 \(E(X) = \sum\limits_{x} xf(x)\)
連続型の場合 \(E(X) = \int_{-\infty}^\infty xf(x)dx\)
と定義されます。

(https://www.netkeiba.com/より引用)
これはとある日の競馬の1レースのオッズ(単勝)と人気順の一部ですが、
例えば人気順に勝率が
1番人気: 40%
2番人気: 20%
3~6番人気: 10%
だとすると、1番人気の馬に賭けて得られるお金の期待値は
\(0.4 \times 2.1倍 + 0.6 \times 0倍 = 0.84倍\)
と計算できます。ほかの馬についても計算してみると…
[ ]:
# 期待値の計算
3.4 * 0.2
5.2 * 0.1
13.5 * 0.1
17.1 * 0.1
17.7 * 0.1
と期待値だけで見ると、5, 6番人気に賭けるのが最適となります。
また、期待値の演算として重要な性質として
\(E(c) = c\)
\(E(X + c) = E(X) + c\)
\(E(cX) = cE(X)\)
\(E(X+Y) = E(X) + E(Y)\)
という性質があります。
5.3.3. 分散と標準偏差
記述統計学を学習した際に、データのばらつきを示す分散や標準偏差という概念を学習しました。
確率変数\(X\)についてもばらつきの概念が存在します。
例えば、
さいころを1個ふった時の目を\(X\)、さいころを2個ふった時の目の平均値を\(Y=(X_1+X_2)/2\)とすると、
\(X\)と\(Y\)の各値が出る確率は下図のようになります。

ここで、それぞれの期待値を求めてみると、
\(E(X) = 1\times\dfrac{1}{6}+2\times\dfrac{1}{6}\cdots6\times\dfrac{1}{6}=\dfrac{7}{2}\)
\(E(Y) = E\{(X_1 + X_2) / 2\} = \{E(X_1) + E(X_2)\} / 2 = \dfrac{7}{2}\)
と等しくなります。しかし、\(X\)の確率分布は1,2,…,6まで一様にばらついているのに対し、\(Y\)の確率分布は期待値に近いところに偏っています。
このように、確率変数の性質は期待値だけではなく、ばらつきもとらえる必要があることがわかります。
ばらつきを表すには、期待値からのずれの大きさ\(X - E(X)\)を考えます。
ずれの大きさの平均(期待値)を求めてみると、\(E(X - E(X)) = E(X) - E(X) = 0\)となってしまい、正負が打ち消されてあまり意味がないので
ずれの値を2乗した\((X - E(X))^2\)を代わりにばらつきの指標として扱います。
\((X - E(X))^2\)の期待値\(E\{(X - E(X))^2\}\)を、確率変数\(X\)の分散\(V(X)=E\{(X - E(X))^2\}\)と定義しています。
分散\(V(X)\)の計算は、
離散型の場合\(V(X) = \sum\limits_{x} (x - E(X))^2f(x)\)
連続型の場合\(V(X) = \int_{-\infty}^\infty (x-E(X))^2f(x)dx\)
で計算できます。
※ 期待値を利用して、\(V(X) = E(X^2) - 2E(X)\times E(X) + (E(X))^2 = E(X^2) - (E(X))^2\) と計算することも可能。
これら期待値や分散は、確率変数の性質を説明する際に使用されます。
実際にサイコロの出る目\(X\)の分散を計算してみると、期待値\(E(X) = 7/2\)だったので、
[ ]:
# サイコロの出る目の分散
x <- c(1, 2, 3, 4, 5, 6)
sum((x - 7/2)^2 * 1/6)
と計算できます。
また、分散の演算として重要な性質として
\(V(c) = 0\)
\(V(X + c) = V(X)\)
\(V(cX) = c^2V(X)\)
\(V(X+Y) = V(X) + V(Y)\)
という性質があります。
5.4. 代表的な確率分布
サイコロの出る目\(X\)やさいころを2個ふった時の目の平均値を\(Y\)の分布をみると分かる通り、確率変数は様々な形の確率の分布に従います。
どの確率変数も同じような確率で出現するものや、平均値付近の値がよく出現する場合など…。
その中でも、特定の現象によく合致する確率分布があり、正規分布、二項分布、ポアソン分布など、いくつかの確率分布が代表的なものとして挙げられます。
ここでは、この中からいくつか代表的な確率分布を紹介していきます。
5.4.1. 正規分布
まずは母集団に仮定する最も一般的な分布である正規分布について見ていきます。
例えば、ある島に生息する平均7㎝くらいを示すシロツメクサの草丈を計測することを考えます。

10個体計測すると左図のようになったとします。これだけだと偶然によるところが大きく、母集団における草丈の分布を想像することが難しいです。次に100個体計測してみると、右図のように中心付近の草丈の個体の出現頻度が高く、両端に行くにしたがって出現頻度がなだらかに低下していくような、釣鐘上の出現頻度を示したとします。この出現頻度からだと、母集団における確率分布も同じような形をしていそうなことが想像できます。
植物の草丈や人の身長など、生物が持つ特性の多くは、このような釣鐘状の分布が見られることが多いです。
このような分布(平均値付近が高く、極端な値になるにつれ出現頻度が下がる)に対して、一般的によくあてはまる確率分布として正規分布 normal distributionがあります。(ガウス分布と呼ばれることもあります。)

正規分布に従う変数が観測値\(x\)をとる確率密度(厳密にいうと確率では無い)は、
\(f(x) = \dfrac{1}{\sigma\sqrt{2\pi}}e^{\lbrace-\frac{(x-\mu)^2}{2\sigma^2}\rbrace}\)
と表されます。ここで、\(\mu\)は平均、\(\sigma^2\)は分散を指す。この関数\(f(x)\)は正規分布の確率密度関数と呼ばれます。
本講義ではこの数式を覚える必要はありませんが、
正規分布は平均と分散が決まればどのような分布になるのかが決まる、という点は理解できるかと思います。
平均\(\mu\)、分散\(\sigma^2\)の正規分布を\(N(\mu, \sigma^2)\)と表記し、確率変数\(X\)がこの正規分布に従うことを
\(X \sim N(\mu, \sigma^2)\)
と表します。
Rを使用することで、確率密度関数の可視化が可能です。
dnorm関数とggplot2を使用することで正規分布の確率密度関数を表すことができます。
dnorm関数はある平均値と分散に従う正規分布の確率密度を計算することができます。
dnorm(xの値, mean=平均値, sd=標準偏差)
たとえば、ある学校の学生の身長の分布が平均\(\mu=170\), 分散\(\sigma=5^2\)の正規分布\(X \sim N(170, 5)\)に従っていた時、下記のようなコードで可視化できます。
[ ]:
# 正規分布の描写
library(ggplot2)
x <- seq(150,190,0.1) # x = 150 ~ 190の範囲を描写
m <- dnorm(x,mean=170,sd=5) # 平均170, 標準偏差5の正規分布
data <- data.frame(x=x,y=m)
g <- ggplot(data,aes(x=x, y=y))
g <- g + geom_line()
g
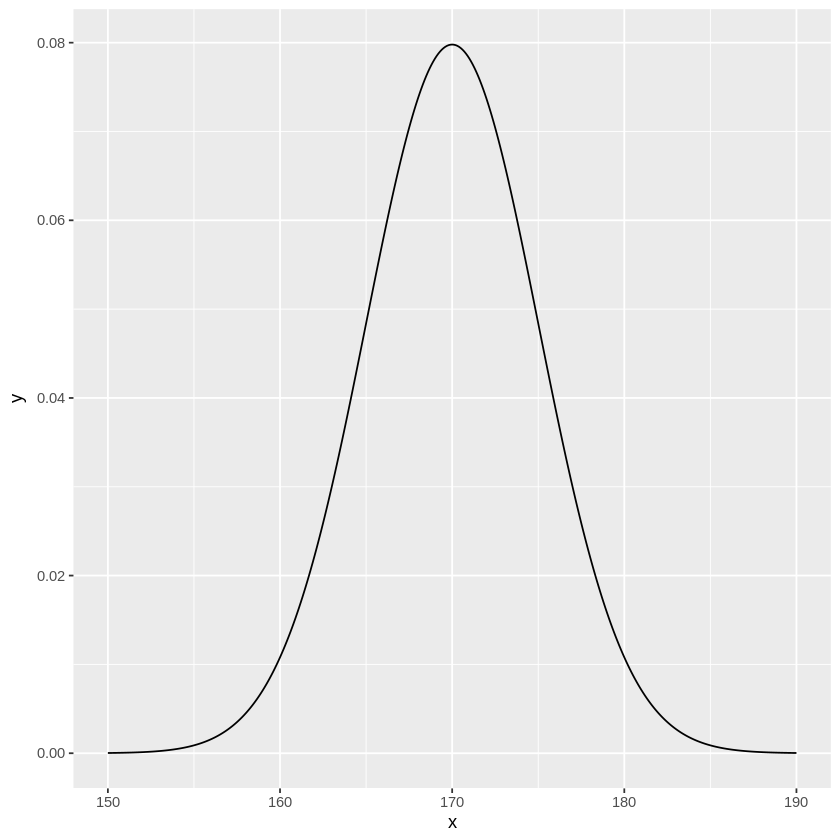
平均値や分散を少し変えた分布を重ねてみると、下のようになります。
[ ]:
# 複数の正規分布を描写
library(ggplot2)
x <- seq(150,190,0.1) # x = 150 ~ 190の範囲を描写
m0 <- dnorm(x,mean=170,sd=5) # 平均170, 標準偏差5の正規分布1
m1 <- dnorm(x,mean=180,sd=5) # 平均180, 標準偏差5の正規分布2
m2 <- dnorm(x,mean=170,sd=10) # 平均170, 標準偏差10の正規分布3
data <- data.frame(x=x, y0=m0, y1=m1, y2=m2)
g <- ggplot(data,aes(x=x))
g <- g + geom_line(aes(y=y0)) # 正規分布1を描写
g <- g + geom_line(aes(y=y1), color="red") # 正規分布2を赤線で描写
g <- g + geom_line(aes(y=y2), color="blue") # 正規分布3を青線で描写
g
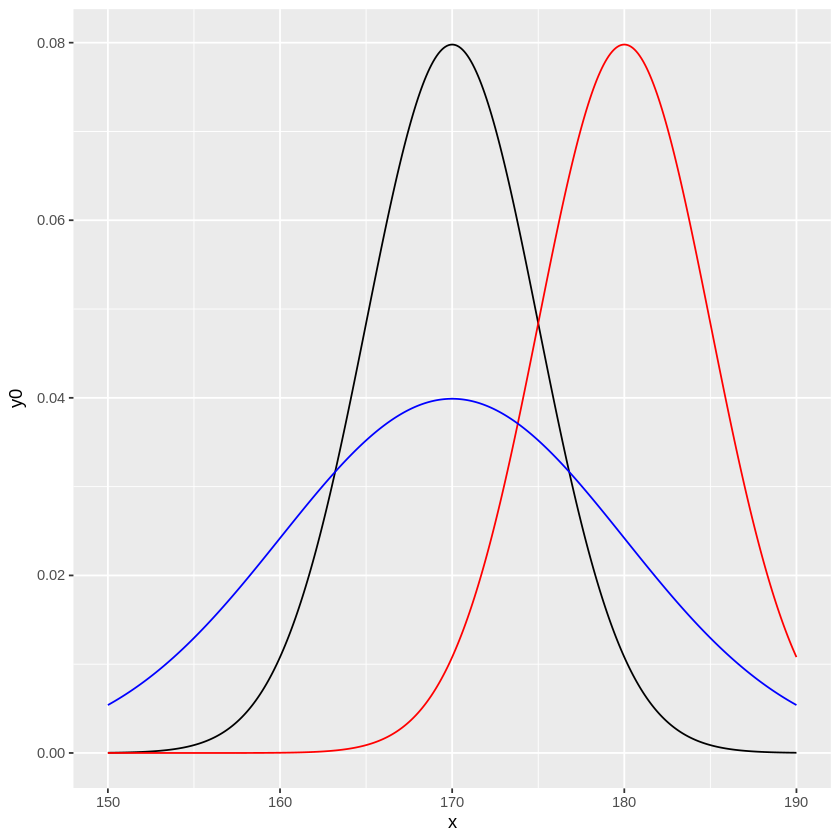

ここで、母集団において、\(x\)以下の値を持つ個体の割合は、
\(F(x) = P(X \leq x) = \int_{-\infty}^{x}f(y)dy\)として得られ、この関数\(F(x)\)は分布関数と呼びます。
Rでは、pnorm関数で計算することができます。
pnorm(xの値, mean=平均値, sd=標準偏差)
例えば先ほどの身長の平均\(\mu=170\), 分散\(\sigma=5^2\)の正規分布\(X \sim N(170, 5)\)で、183以下の確率は下記のように計算できます。
[ ]:
# 平均170,標準偏差5の正規分布における183以下の確率
pnorm(183,170,5)
図として表すと、下図の様になります。
[ ]:
# 183以下の領域を可視化
library(ggplot2)
x <- seq(150,190,0.1)
y <- dnorm(x, 170, 5)
data <- data.frame(x=x, y=y)
x_color <- seq(150,183,0.1)
y_color <- dnorm(x_color, 170, 5)
data_color <- data.frame(x=x_color, y=y_color)
g <- ggplot()
g <- g + geom_path(data=data, aes(x=x, y=y))
g <- g + geom_ribbon(data=data_color, aes(x=x, y=y, ymin=0, ymax=y))
g
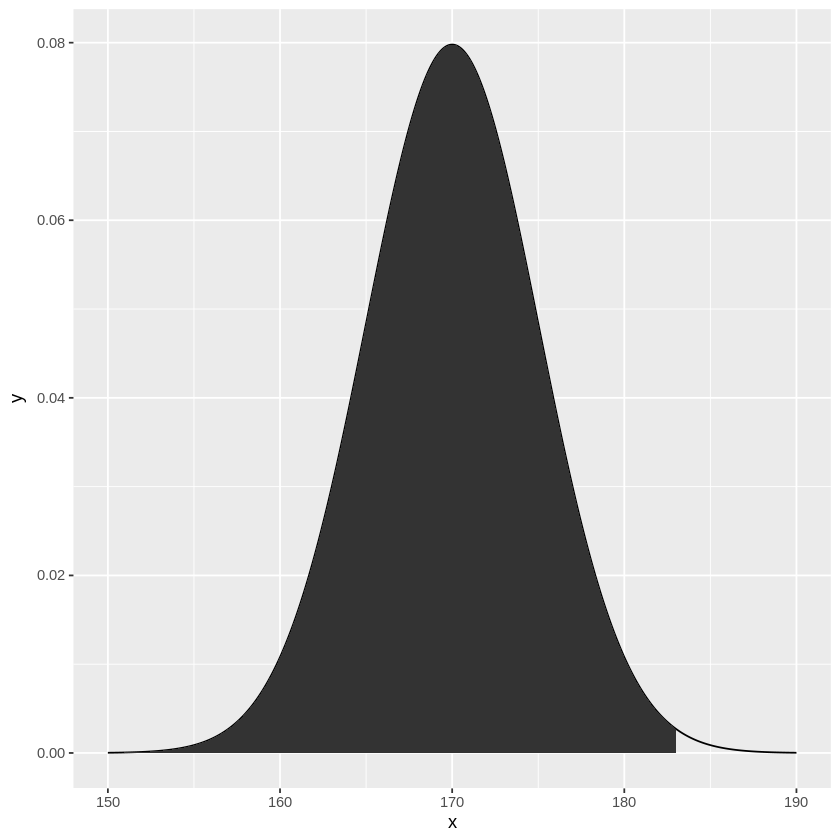
では、下図の様な165以上180以下の身長の確率はどう計算すればよいでしょうか?

これもpnorm関数を用いることで計算できます。
[ ]:
# 165~180の範囲の確率を求める
pnorm(180,170,5) - pnorm(165,170,5)
この様に、正規分布に従う変数\(X\)について、pnorm関数を使用することで、得られた観測値\(x\)がある値の範囲内である確率を計算することができます。
また、ある正規分布に従う母集団から無作為に抽出した結果をシミュレートすることもできます。
Rのrnorm関数で実施できます。
rnorm(n=抽出数, mean=平均値, sd=標準偏差)
平均\(170\)、分散\(5^2\)の正規分布から5標本無作為に抽出してみると…
(無作為抽出なので動かすごとに結果は変わります。)
[ ]:
# 平均170 標準偏差5の正規分布から5標本をランダムに抽出する
rnorm(n=5, mean=170, sd=5)
- 170.65229671653
- 168.375173912678
- 171.778591588002
- 164.512905411614
- 167.715986459784
といった形で抽出できます。
5標本抽出した結果からヒストグラムを描いてみると
[ ]:
# 平均170 標準偏差5の正規分布から5標本をランダムに抽出し、ヒストグラムを描く
hist(rnorm(n=5, mean=170, sd=5))
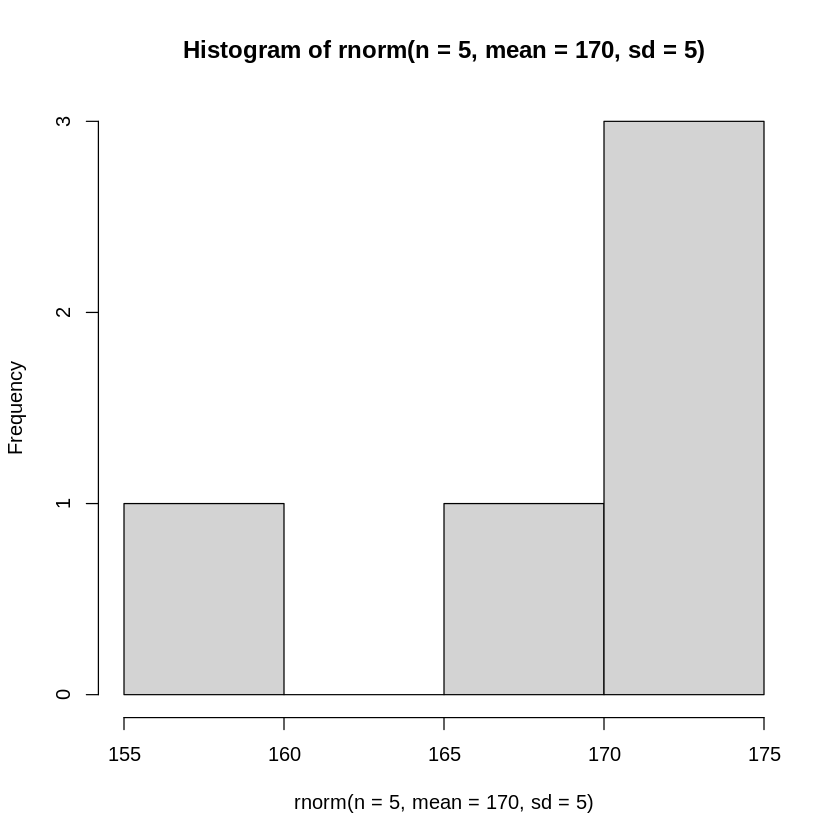
と全く正規分布しているようには見えません。サンプルサイズが限られている場合、母集団が正規分布に従っていたとしても、標本データからそのことは分からない場合が多々あります。
標本データから得られる標本分布は、サンプルサイズが小さいと、あまり意味がないことに注意が必要です。
サンプルサイズが非常に大きければ標本から得られるヒストグラムは母集団の分布に近づいていきます。
例えば10,000個体標本抽出をした場合を見てみましょう。
[ ]:
# 平均170 標準偏差5の正規分布から10000標本をランダムに抽出する
hist(rnorm(n=10000, mean=170, sd=5), breaks=100)
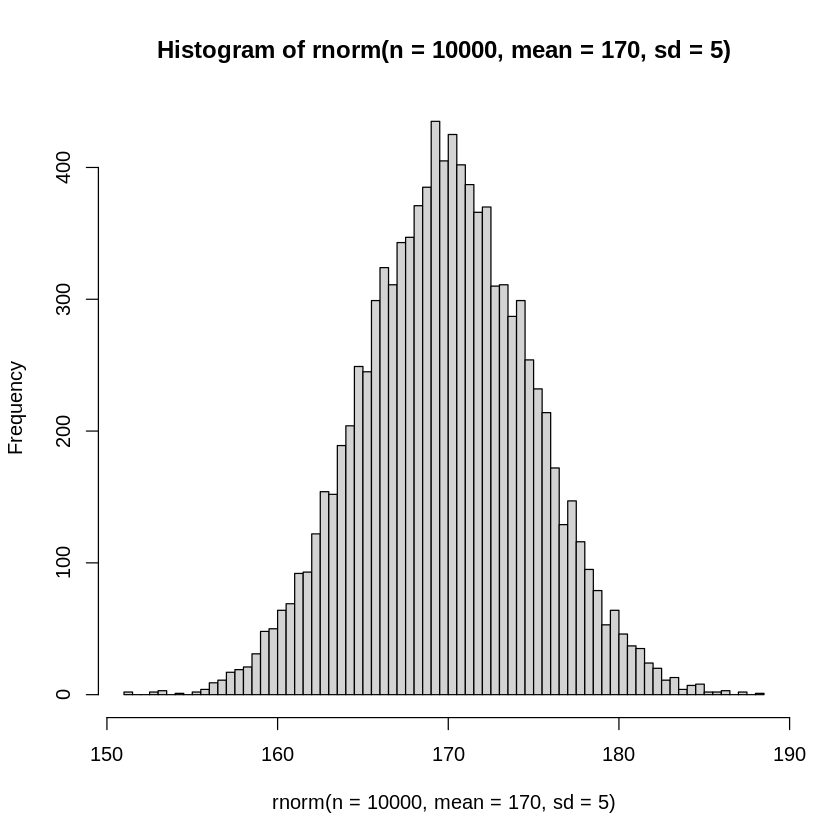
この様に、かなり正規分布に近いヒストグラムが得られました。
ここまで、いくつか正規分布に関係するRの関数を扱ってきたのでまとめておきます。

dnorm… ある正規分布における各値の確率密度を計算出来る
dnorm(xの値, mean=平均値, sd=標準偏差)
pnorm… \(x\)以下の値を持つ確率、分布関数の計算が出来る
pnorm(xの値, mean=平均値, sd=標準偏差)
rnorm… 正規分布からのランダムな標本抽出が出来る
rnorm(n=抽出数, mean=平均値, sd=標準偏差)
qnorm… (初登場)パーセンタイル値、分布関数である確率になる:math:xの値が求まる(pnormの逆)
qnorm(確率の値, mean=平均値, sd=標準偏差)
例えば第3回で扱った偏差値を例にすると、
仮にある試験の偏差値が平均値が50、標準偏差が10の正規分布\(N(50, 10)\)に従っていたとします。
[ ]:
# 偏差値の分布の描写
library(ggplot2)
x <- seq(0,100,0.1) # x = 0 ~ 100の範囲を描写
m <- dnorm(x,mean=50,sd=10) # 平均50, 標準偏差10の正規分布
data <- data.frame(x=x,y=m)
g <- ggplot(data,aes(x=x, y=y))
g <- g + geom_line()
g
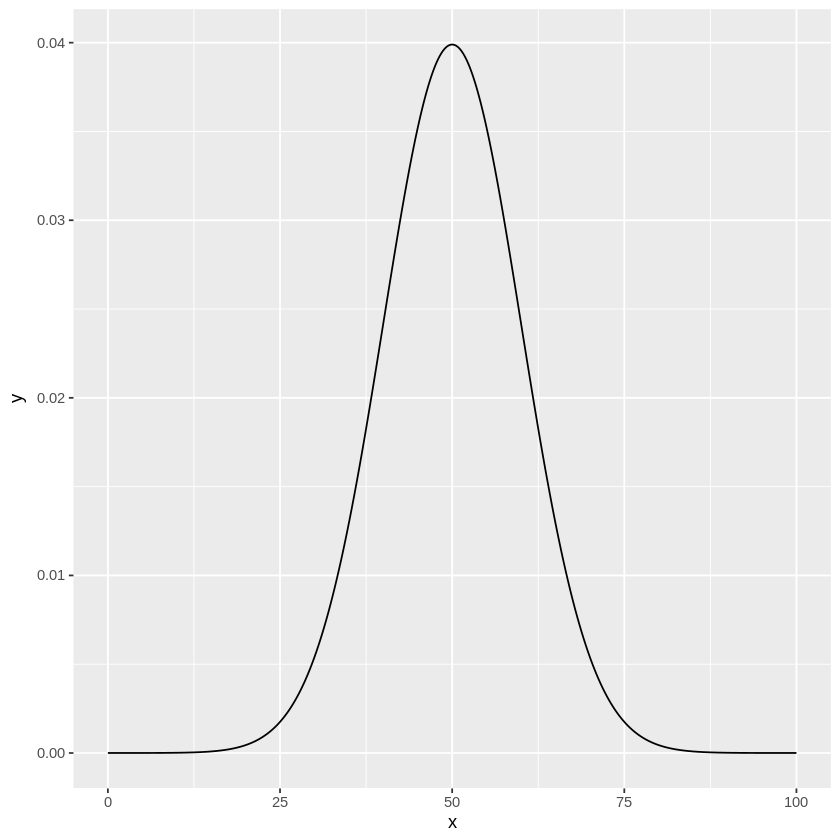
この分布において、偏差値が60以下の人達の割合を求めると…
[ ]:
# 平均50, 標準偏差10の正規分布で、60以下の割合を求める
pnorm(60, 50, 10)
また、95%の人が含まれる偏差値xを求めると…
[ ]:
# 平均50, 標準偏差10の正規分布で、分布関数で確率が95%になるxの値を求める
qnorm(0.95, 50, 10)
といった形で各種関数を活用します。
また、これらの関数名のnormを別の確率分布名に入れ替えたdxxxx, pxxxx, rxxxx, qxxxxという関数が後ほど別の確率分布を扱う際に登場します。
5.4.1.1. 標準正規分布
正規分布の中でも、平均\(\mu=0\), 分散\(\sigma=1^2\)の正規分布\(N \sim N(0, 1)\)を特に標準正規分布と呼び、\(\phi(z)\)で表します。
この分布は、 \(\phi(z) = \dfrac{1}{\sqrt{2\pi}}exp\lbrace-\frac{z^2}{2}\rbrace\)と表され、代表的な分布として主な区間の確率がよく知られています。
例えば、\(P(-1 \leqq Z \leqq 1)\)をpnorm関数で求めると、
[ ]:
# 標準正規分布(平均0, 分散1)における-1から1の確率を求める
pnorm(1, 0, 1) - pnorm(-1, 0, 1)
この様に、標準偏差の\(k\)倍の範囲をそれぞれ求めていくと下記の様な確率が求まります。
\(P(-1 \leqq Z \leqq 1)\) … 0.6827 (約1/3)
\(P(-2 \leqq Z \leqq 2)\) … 0.9545 (約1/20)
\(P(-3 \leqq Z \leqq 3)\) … 0.9973 (約3/1000)

これらの値から、平均値から標準偏差の3倍である\(3\sigma\)を超える様な値は極めて起こりにくいことが分かります。
平均\(\mu\)、分散\(\sigma^2\)の正規分布\(N(\mu, \sigma^2)\)に従う変数\(X\)は、\(Z = \dfrac{X-\mu}{\sigma}\)という変数の変換を行うことで、
標準正規分布に従う変数\(Z \sim N(0, 1)\)となります。この変換を標準化と呼びます。
どんな正規分布でも標準化することで平均0、標準偏差1の標準正規分布に変換できるので、異なる平均と標準偏差を持つ正規分布のデータを比較したり、上の範囲などをもとに確率を捉えたりすることが容易になります。
5.4.2. 二項分布
続いて、離散型の確率変数の代表的な分布である二項分布について触れます。

例えば、ある地域にはシロツメクサの中でも白色のものと薄紅色のものが生息しています。薄紅色のものが20%(\(p=0.2\))、白色のものが80%(\(q=0.8\))生息しているとします。
この時、無作為に4個体シロツメクサを採集すると、薄紅色のシロツメクサの個体数Xは0,1,2,3,4のいずれかの値をとる確率変数になります。

それぞれが起きる確率としては、
\(P(x=0) = _4C_0p^0q^4=1 \times 0.8^4 = 0.4096\)
\(P(x=1) = _4C_1p^1q^3=4 \times 0.2 \times 0.8^3 = 0.4096\)
\(P(x=2) = _4C_2p^2q^2=6 \times 0.2^2 \times 0.8^2 = 0.1536\)
\(P(x=3) = _4C_3p^3q^1=4 \times 0.2^3 \times 0.8 = 0.0256\)
\(P(x=4) = _4C_4p^4q^0=1 \times 0.2^4 = 0.0016\)
となり、\(X\)の取りうる値全ての確率の和\(\sum_{k=0}^4 P(X=k)\)が\(1\)になっています。

この様な、母集団がAとBの2種類に分けられ、それぞれの種類に属する要素の割合が\(p\)および\(q=1-p\)であるとき、
大きさ\(n\)から成る標本集団にAの標本が\(x\)個含まれる確率は
\(f(x) = _nC_xp^x(1-p)^{n-x}=\dfrac{n!}{x!(n-x)!}p^x(1-p)^{n-x}\)
と表せます。
正規分布の際はこのような式を確率密度関数と呼びましたが、離散型確率変数の場合は確率関数と呼びます。
この確率関数に従う分布を二項分布binomial distributionと呼び\(Bi(n, p)\)と表します。
二項分布\(Bi(n, p)\)に従う確率変数\(X\)の平均(期待値)と分散は、
\(E(X) = np\)
\(V(X) = np(1-p)\)
で表されます。
平均に関しては、\(p\)の確率で出現する個体は\(n\)個体サンプリングすれば\(n\times p\)個体くらいは出てきそう、と直感に合う形です。
分散についても、\(p=\dfrac{1}{2}\)(50%)の時に一番バラバラな結果が得られそう(分散が大きい)だと直感的に理解できます。
正規分布同様、二項分布もRの関数で確率などの計算が容易にできます。
dbinom関数で確率が\(p\)の事象を\(n\)回試行する二項分布\(Bi(n, p)\)において、その事象が\(x\)回起きる確率を計算出来ます。
dbinom(x, size=試行回数, prob=事象の確率)
例えば、80%の確率で勝つ勝負を10回繰り返したときに、10回勝つ事が出来る確率は…
[ ]:
# n=10, p=0.8の二項分布でx=10の確率を求める
dbinom(10, size=10, prob=0.8)
dbinom関数で1 ~ 10回それぞれの確率を計算してグラフ化してみると下図のようになります。
[ ]:
# 二項分布の描写
library(ggplot2)
x <- seq(1,10,1) # x = 1 ~ 10の範囲を描写
m <- dbinom(x,size=10,prob=0.8) # 試行回数10, 確率0.8の二項分布
data <- data.frame(x=x,y=m)
g <- ggplot(data,aes(x=x, y=y))
g <- g + geom_bar(stat = "identity", position = "dodge", fill = "#00A968") # 棒グラフを追加
g <- g + theme(text = element_text(size = 18)) # フォントサイズ変更
g <- g + scale_x_continuous(breaks = seq(1,10,1)) # 軸ラベル追加
g
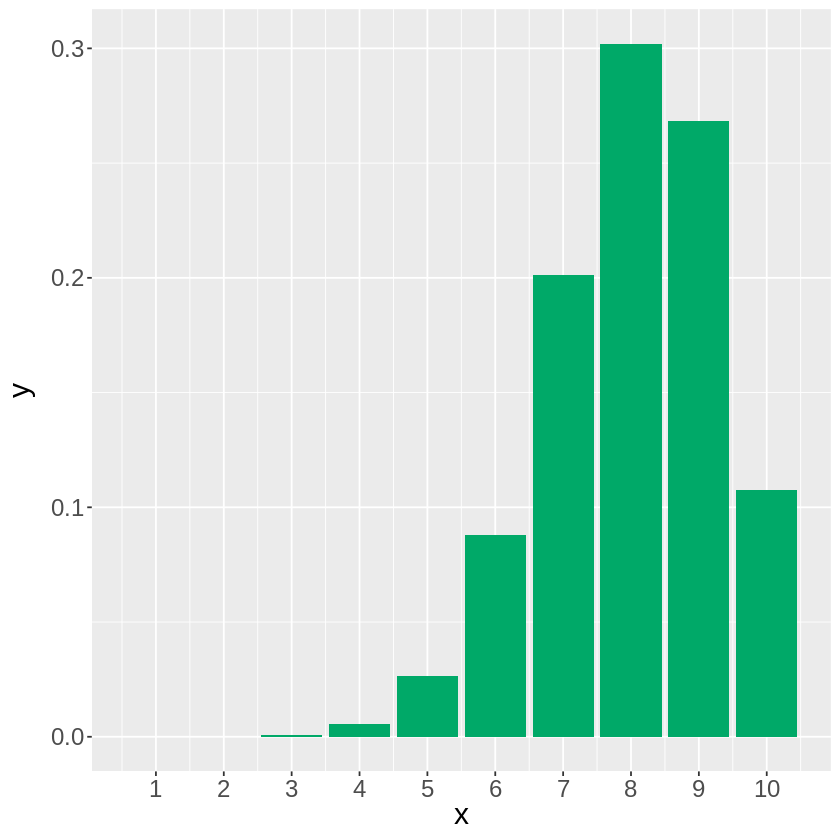
また、pbinom関数を使えば、二項分布の累積分布関数を計算出来ます。
その事象が\(x\)回以下生じる確率の合計を求めます。
pbinom(x, size=試行回数, prob=事象の確率)
80%の確率で勝つ勝負を10回繰り返したときに、多くとも5回しか勝つ事が出来ない確率は…
[ ]:
# n=10, p=0.8の二項分布でxが5以下の確率を求める
pbinom(5, 10, 0.8)
pbinom関数を使用すれば、80%の確率で勝つ勝負を10回繰り返したときに、5回または6回勝つ確率、等も求められます。
[ ]:
# n=10, p=0.8の二項分布でxが5か6の確率を求める
pbinom(6, 10, 0.8) - pbinom(4, 10, 0.8)
正規分布の時と同じように、ランダムサンプリングが出来るrbinom関数やパーセンタイル点を求めるqbinom関数もあります。
rbinom関数は二項分布に従う乱数を\(n\)個生成します。
rbinom(n, size=試行回数, prob=事象の確率)
qbinom関数は、指定した累積確率\(p\)になる最小の成功回数を求めます。
qbinom(p, size=試行回数, prob=事象の確率)
[ ]:
# n=10, p=0.8の二項分布から無作為に7回抽出する
rbinom(7, 10, 0.8)
- 9
- 10
- 8
- 8
- 9
- 9
- 9
[ ]:
# n=10, p=0.8の二項分布で、累積確率が0.5になる回数を求める
qbinom(0.5, 10, 0.8)
この様に、各確率分布毎にRの関数が用意されています。例: dnorm, dbinom
それぞれの確率分布の形を決めるパラメータを指定することで関数が使用できます。
確率分布の形は
正規分布\(N(\mu, \sigma)\)の場合は、平均値と標準偏差。
二項分布\(Bi(n, p)\)の場合は、試行回数と事象の確率
によって形が決まります。
5.4.3. ポアソン分布
二項分布において、\(n\)が大きく(大量に観察を行い)、\(p\)が小である(極めて珍しい現象がある)場合を考えると、
現象自体は珍しいものの観察数が多いので、ある程度\(x\)が観察される場合があります。
例えば、交通事故などが例に挙げられます。(交通事故自体が起きる確率は稀だが、交通量が多いためそれなりに事象としては観察される。)
外出した際に交通事故にあう確率が\(p = 0.0001\)(0.01%)として、10000回(約27年間毎日)外出した際に交通事故に1度あう確率を計算してみると、その確率は二項分布の式から、
\(f(1) = _{10000}C_1(0.0001)^1(0.9999)^{9999}\)
で計算できます。dbinom関数で計算してみると…
[ ]:
# n=10000, p=0.0001の二項分布でx=1となる確率を求める
dbinom(1, size=10000, p=0.0001)
と、それなりの確率で起きる事象だと分かります。
二項分布の期待値\(E[X]=np=10000\times0.0001=1\)というところからも、\(x=1\)の確率はそれほど低くないと考えられます。
この様な、膨大な観察数を行うことで得られる、極めて起きる確率が低い事象の起きる数である確率変数\(X\)は、
二項分布にしたがうだけでなく、ポアソン分布と呼ばれる確率分布に限りなく近づくことが知られています。
詳細な計算は省きますが、\(np\to\lambda\)となるように\(n\to\infty, \space p\to0\)となる極限においては、
\(_nC_xp^x(1-p)^{n-x}\to e^{-\lambda}\dfrac{\lambda^x}{x!}\)
が成り立つことがポアソンの小数の法則として知られています。ここで、
\(f(x) = e^{-\lambda}\dfrac{\lambda^x}{x!}\)という確率関数に従う分布をポアソン分布Poisson distributionと呼び、\(Po(\lambda)\)で表します。
ポアソン分布\(Po(\lambda)\)に従う確率変数\(X\)の期待値と分散は、
\(E(X) = \lambda\)
\(V(X) = \lambda\)
となり、期待値と分散が等しくなることがポアソン分布の特徴です。
ポアソン分布に関係するRの関数はdpois, ppois, rpois, qpoisになります。
ポアソン分布\(Po(\lambda)\)の形を決めるパラメータは\(\lambda = np\)だけになります。
例えば先ほどの交通事故にあう確率が\(p = 0.0001\)として、10000回外出した場合を考えると、
\(np = 0.0001 \times 10000 = 1\)
となるので、交通事故にあう回数は\(Po(1)\)にある程度従うと考えられます。
ポアソン分布に従う事象が\(x\)回起きる確率はdpois関数で計算できます。
dpois(x, lambda=ラムダ値)
起きる回数が\(Po(1)\)に従う事象が1度起きる確率を計算すると…
[ ]:
# ラムダ=1のポアソン分布に従う事象が1回生じる確率
dpois(1, lambda=1)
と二項分布で計算した場合と非常に近い値となりました。
\(x=0 \sim 10の範囲で\)ポアソン分布\(Po(1)\)のグラフを描いてみると下図のようになります。
[ ]:
# ポアソン分布の描写
library(ggplot2)
x <- seq(0,10,1) # x = 0 ~ 10の範囲を描写
m <- dpois(x,lambda=1) # ラムダ=1のポアソン分布
data <- data.frame(x=x,y=m)
g <- ggplot(data,aes(x=x, y=y))
g <- g + geom_bar(stat = "identity", position = "dodge", fill = "#00A968") # 棒グラフを追加
g <- g + theme(text = element_text(size = 18)) # フォントサイズ変更
g <- g + scale_x_continuous(breaks = seq(0,10,1)) # 軸ラベル追加
g
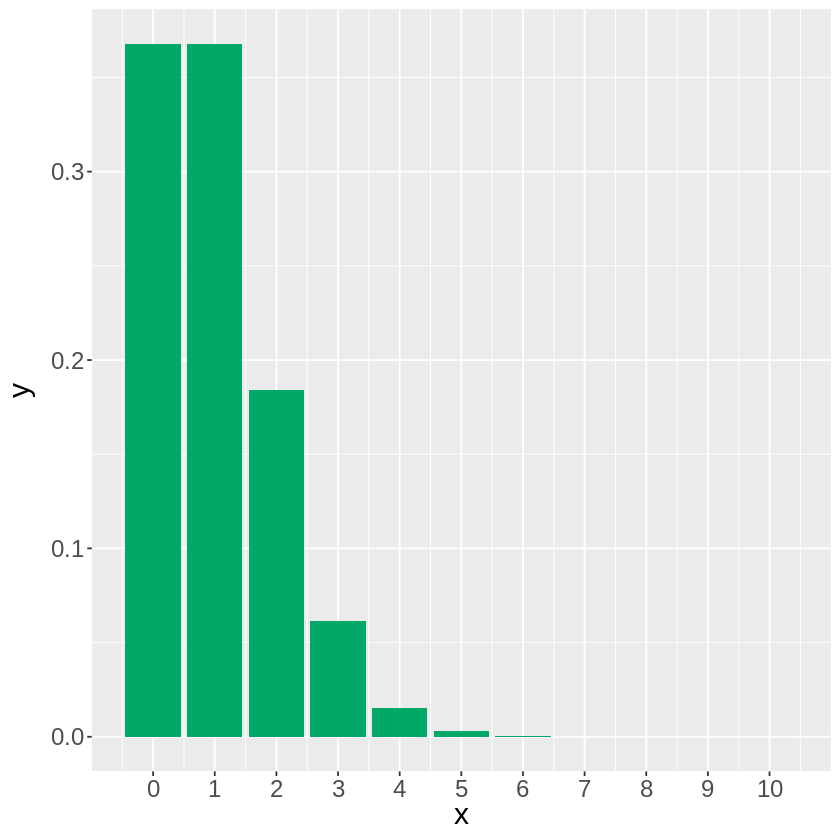
これまで同様、1回から6回のいずれかの回数この事象が起きる確率をppois関数で計算してみると
[ ]:
# ラムダ=1のポアソン分布に従う事象が1~6回のいずれか生じる確率
ppois(6, lambda=1) - ppois(0, lambda=1)
それなりの確率で交通事故に遭うかもしれないということが分かります。
5.4.3.1. 二項分布とポアソン分布の関係
さて、ここまでRの関数を使用できたので、ややこしい計算をする必要がありませんでした。
そのため、二項分布をポアソン分布で近似する必要性を感じられなかったかもしれないですが、
実際に計算することを考えると、この近似はとても便利なことが分かります。

例えば、ある地域では0.2%の確率で四葉のクローバーが出現するとします。
四葉のクローバーを求めてシロツメクサを500個体採集した際に、四葉のクローバーが2個体採集できる可能性を考えてみます。
二項分布でまず考えてみると、この条件で観察される四葉のクローバーの数である確率変数\(X\)は\(p=0.002, n=500\)の二項分布に従います。
\(X \sim Bi(500, 0.002)\)
この時、採集した500個体の中に2個体四葉がある確率は
\(f(x=2)=_{500}C_2(0.002)^2(0.998)^{498}\)となります。
関数を使わず素直にRで計算してみると
[ ]:
# 500個体中0.2%の個体が2個体いる確率
500*499/2*(0.002^2)*(0.998^498)
続いて、ポアソン分布を用いて考えてみます。見つかる確率\(p\)は小さく、観察数\(n\)は大きいので、この確率変数の確率分布は
パラメータが、\(\lambda = np = 500 \times 0.002 = 1\)であるポアソン分布に近似できると考えられます。
確率変数\(X\)は\(\lambda=1\)のポアソン分布\(Po(1)\)に従うので、
\(f(x) = e^{-1}\dfrac{1^x}{x!}\)に従う形になります。
この場合、500個体中2個体が四葉である確率は
\(f(x=2) = e^{-1}\dfrac{1^2}{2!}\)となります。
こちらも関数を使わず素直にRで計算してみると
[ ]:
# ポアソン分布Po(1)に従う個体数が2個体の確率を求める
exp(-1) * 1 / 2
といった形で、二項分布より簡単な計算でほぼ等しい確率が計算できました。
ポアソン分布を仮定できる現象は非常に多く、上述した交通事故や珍しい形質を持つ個体の数だけでなく、
遺伝子の突然変異数や顕微鏡視野に入るバクテリア数など、様々な生物現象に仮定としておくことができます。
5.4.4. そのほかの分布
代表的な分布として、正規分布、二項分布、ポアソン分布を紹介しました。
他にも負の二項分布、一様分布、\(\chi^2\)分布、指数分布、ガンマ分布など様々な分布が存在しています。
また、二項分布とポアソン分布の関係性のように、分布同士でつながりの強いものも多いです。
確率論を勉強していくと一通り学ぶことになりますし、こういった↓まとめも探すと見つけることが出来るかと思います。 https://www.math.wm.edu/~leemis/chart/UDR/UDR.html
本講義では全て取り上げるとキリがないのでこのあたりにしておきますが、
各種統計手法の理解のために必要な分布(\(t\)分布や\(F\)分布、\(\chi^2\)分布など)については、その項目を扱う際に触れたいと思います。
5.5. 大数の法則と中心極限定理
最後に、確率論の定理の中でも、統計学の上で大きな意味合いを持つ大数の法則と中心極限定理について触れておきます。
5.5.1. 大数の法則
大数の法則とは、試行回数が増えるにつれて、実際に得られる確率が理論上の確率に近づくという法則を指します。
当たり前の様な気がしますが、実際の例でみてみましょう。
例えば、先ほどの生息しているシロツメクサの20%が薄紅色で80%が白色の地域において、10個体標本を採集した時に観察される薄紅色のシロツメクサの数を考えてみます。
薄紅色の個体数\(X\)は二項分布\(Bi(10, 0.2)\)に従うので、薄紅色の個体が0,1,2,…9,10個体観察される確率をそれぞれ計算してグラフ化してみると
[ ]:
# 観察数10, 事象の確率0,2の二項分布
n = 10
p = 0.2
x <- seq(0, n, 1) # 0 ~ 10個体
m <- dbinom(x, size = n, prob = p) # n=10, p=0.2の二項分布における確率
data <- data.frame(x=x,y=m)
g <- ggplot(data,aes(x=x, y=y))
g <- g + geom_bar(stat = "identity", position = "dodge", fill = "#00A968") # 棒グラフを追加
g <- g + theme(text = element_text(size = 18)) # フォントサイズ変更
g <- g + scale_x_continuous(breaks = seq(0,10,1)) # 軸ラベル追加
g <- g + geom_vline(xintercept = 10*0.2) # 理論上観察される値(n x p)に縦線
g
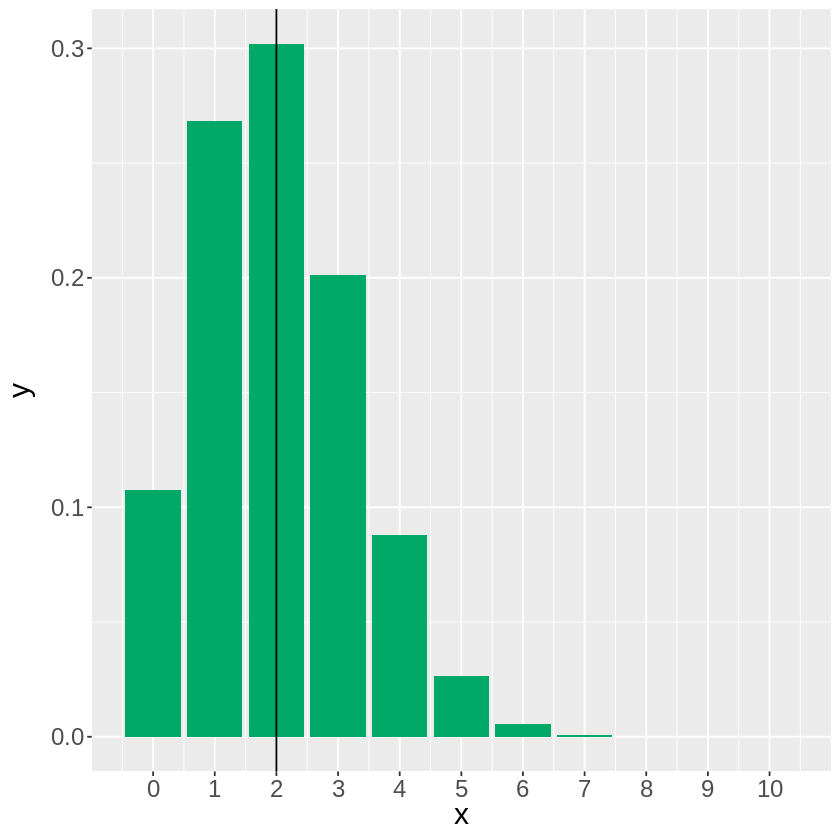
となり、実際の確率(薄紅色が20%)通りに個体が出た場合の、10個体中2個体得られる確率は30%ほどしかないことがわかります。
ここで採集する個体の数を、100個体、1000個体、、、と増やしていくとどうなるか見ていきます。
[ ]:
# 観察数n, 事象の確率0,2の二項分布のnを増やしていくとどうなるか
n = 100
p = 0.2
x <- seq(0, n, 1) # 0 ~ n個体
m <- dbinom(x, size = n, prob = p) # n, p=0.2の二項分布における確率
data <- data.frame(x=x,y=m)
g <- ggplot(data,aes(x=x, y=y))
g <- g + geom_bar(stat = "identity", position = "dodge", fill = "#00A968") # 棒グラフを追加
g <- g + theme(text = element_text(size = 18)) # フォントサイズ変更
g <- g + geom_vline(xintercept = n*0.2) # 理論上観察される値(n x p)に縦線
g
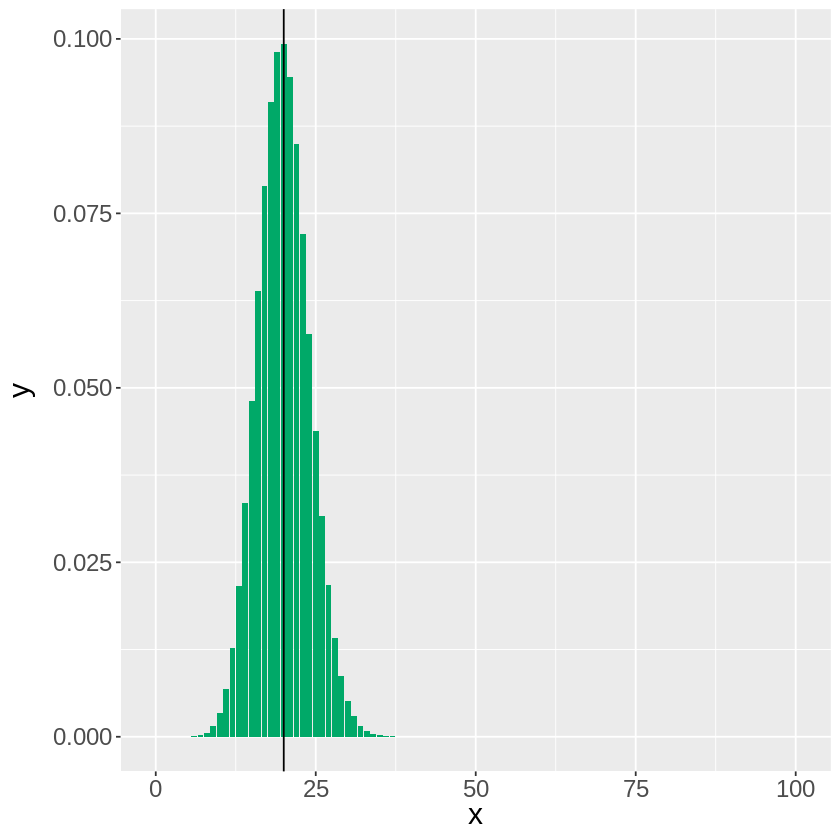
この様に、観測される結果が理論上の確率付近に集中していきます。これを大数の法則と呼びます。
注意点としては、先ほどの例でいうと1000個体採集した場合も理論値である\(1000 \times 0.2 = 200\)に収束しているわけではないので、採集数が増えれば理論上の観測値に収束するというわけではなく、近傍にある確率が極めて高くなることを意味します。
この法則は、十分な大きさの標本集団を調べれば、母集団の様々な特性をかなり正確に知ることができるということを示しており、統計的推測において非常に重要な定理になります。
5.5.2. 中心極限定理
中心極限定理とは、母集団がどのような分布であっても、標本サイズ:math:`n`が大きくなると、和:math:`X_1+X_2+X_3+…+X_n`(or平均とする場合もある)の分布は正規分布に近似できる、という定理になります。
実際に先ほどの二項分布に従う変数\(X \sim Bi(n, 0.2)\)で見てみましょう。
20%が薄紅色で80%が白色のシロツメクサが生息している地域で標本を 100個体採集して薄紅色の個体が何個体あるかは\(Bi(100, 0.2)\)に従います。
これを別の見方で考えると、1個体採集して薄紅色の個体が何個体あるか(薄紅色かどうか)が従う\(X \sim Bi(1, 0.2)\)を100回繰り返したものとも考えられます。
つまり、
1個体目が薄紅色であれば\(X_1 = 1\)
2個体目が白色であれば\(X_2 = 0\)
…
100個体目が薄紅色であれば\(X_{100} = 1\)
として、得られた観察結果の和\(X_1 + X_2 + ... + X_{100}\)を\(Bi(100, 0.2)\)は表しています。
つまり\(Bi(n, 0.2)\)の分布は\(X \sim Bi(1, 0.2)\)を\(n\)回繰り返した合計の分布と考える事が出来ます。
そのため、標本サイズ\(n\)が大きいほど正規分布に近付けば中心極限定理が成り立っていると考えられます。
下のコードの\(n\)の数字を大きくしていくと、和\(X_1 + X_2 + ... + X_n\)の分布が正規分布に近付くことが分かると思います。
[ ]:
# 中心極限定理、二項分布の場合
n = 5
p = 0.2
x <- seq(0, n, 1) # 0 ~ 10個体
m <- dbinom(x, size = n, prob = p) # n, p=0.2の二項分布
data <- data.frame(x=x,y=m)
g <- ggplot(data,aes(x=x, y=y))
g <- g + geom_bar(stat = "identity", position = "dodge", fill = "#00A968") # 棒グラフを追加
g <- g + theme(text = element_text(size = 18)) # フォントサイズ変更
g
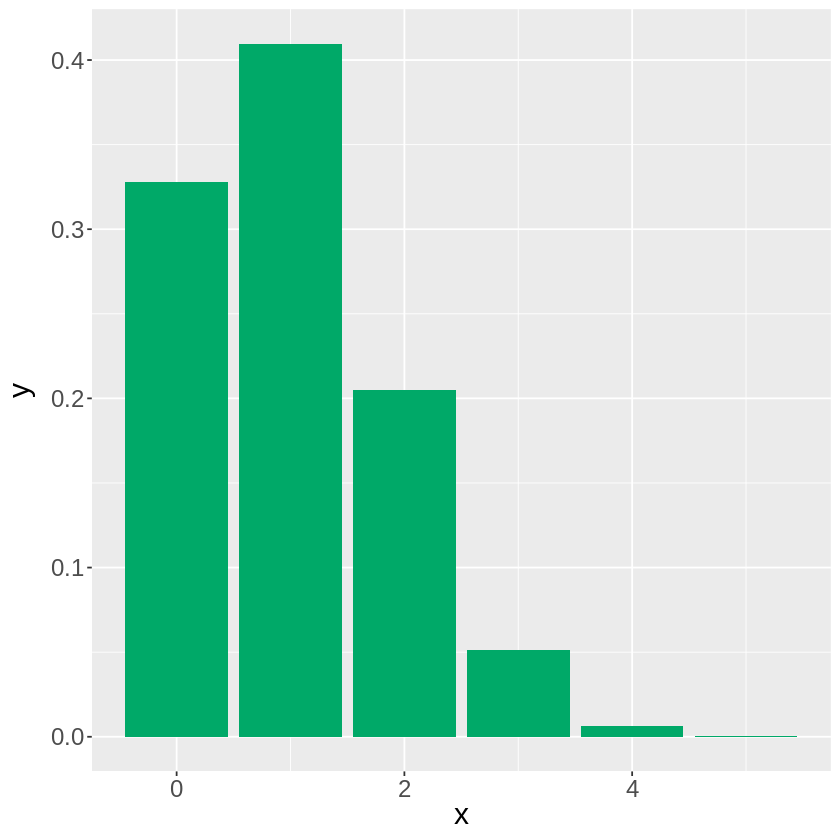
ポアソン分布\(Po(\lambda)\)についても見てみます。
交通事故にあう確率が\(p = 0.0001\)として、10000回外出した場合何回事故に遭うかは\(Po(1)\)に従いました。
そして、\(Po(1)\)に従う数値をランダム抽出するには
rpois(n, lambda=ラムダ値)
で抽出できました。
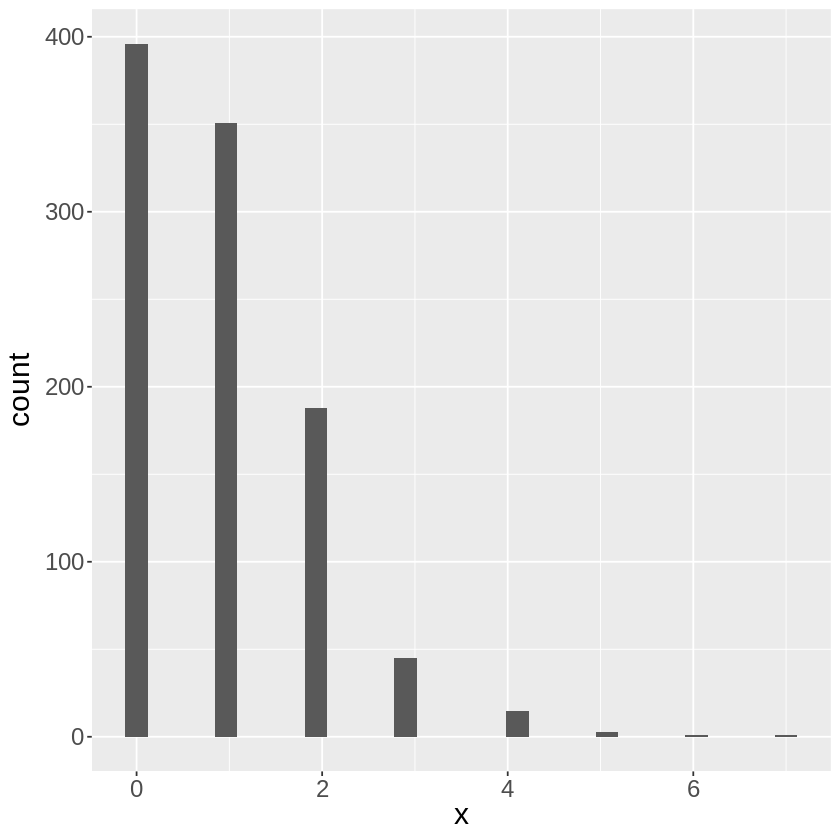
1人調査した場合はrpois(1, lambda=1)、10人調査した場合はrpois(10, lambda=1)、
100人調査した場合はrpois(100, lambda=1)という形になります。
[ ]:
# ラムダ=1のポアソン分布に従う事象を10人分調査した場合
rpois(10, lambda=1)
- 1
- 1
- 1
- 0
- 1
- 1
- 1
- 0
- 1
- 0
この合計値が調査人数が増えるほど正規分布に近付くというわけです。
下のコードの\(n\)の数値を変えて見てみましょう。
[ ]:
# 中心極限定理、ポアソン分布の場合
n = 1
x <- c()
for (i in 1:1000) {
x <- c(x, sum(rpois(n, 1)))
}
data <- data.frame(x=x)
g <- ggplot(data, aes(x=x))
g <- g + geom_histogram()
g <- g + theme(text = element_text(size = 18))
g
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
他の分布、例えば下の様な、少し変わった分布に植物の草丈が従う母集団がいたとします。
[ ]:
# 二峰型の分布
gene <- function(n){
prob <- (runif(n) <= 0.6)
rlnorm(n,2,0.5) *prob+rnorm(n,30,5)*(1-prob)
}
height_all <- round(gene(100000))
hist(height_all,xlim=c(0,60),main ="Plant height",xlab="height(cm)",ylab="samples",breaks=seq(0,10000,1))
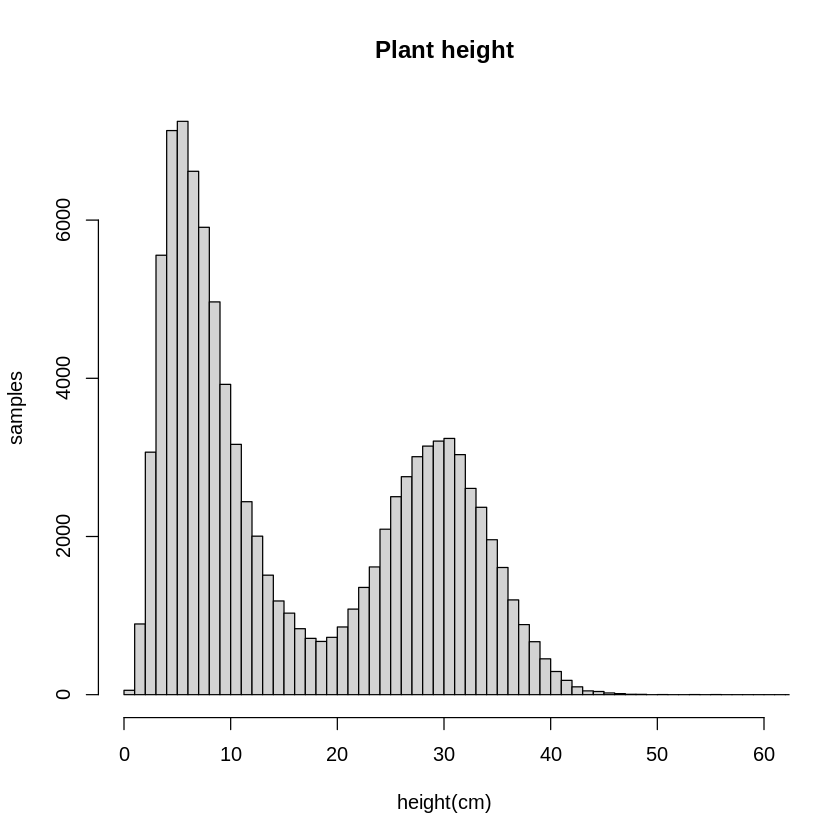
5cmくらいの植物と、30cmくらいの植物が混在している集団でしょうか。
この分布に従う植物集団から、\(n\)個体の標本を採集し、その草丈の合計\(X_1+X_2+...+X_n\)の分布を考えてみます。
下のコードは、この分布からランダム抽出した個体の合計値の分布を示しています。
\(n\)の部分を増やしていくことで、合計の分布がどうなっていくか見てみましょう。
[ ]:
# 中心極限定理、二峰型の分布の場合
n <- 1
sum_values <- c()
for(i in 1:1000){
samples <- sample(height_all,n,replace = FALSE)
sum_values <- c(sum_values,sum(samples))
}
hist(sum_values)
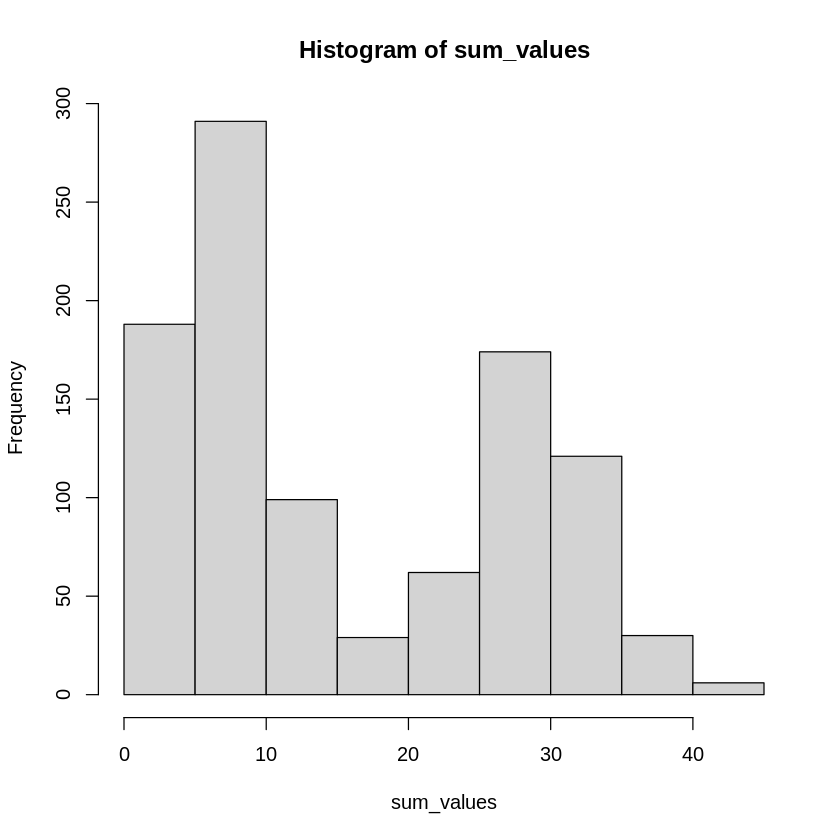
この様に、母集団がどのような分布であったとしても、標本サイズ\(n\)が大きくなると、その和(平均)の分布が正規分布に近付いていきます。
この中心極限定理により、母集団の分布が不明な場合でも、真の平均値が大体どの範囲に収まっているかを推定する「区間推定」や、区間推定の考え方を応用して仮説を検証する「検定」を行うことができるようになります。
そのため、中心極限定理は統計的推測の強力な基盤となっています。
5.6. 標本分布
では実際に標本抽出によって得られた標本のデータと母集団の関係などについて触れていきます。
最初の方でも触れましたが、これから特徴を知りたい集団全体を母集団と呼びました。
統計的推測では、抽出した標本からこの母数を推定することが1つの目的になります。
5.6.1. 確率や分布が必要な理由
当然ながら、標本を分析して得られる結果は、抽出された標本によって異なる可能性があります。
仮に、ある公園に生えている植物が5個体(植物1-5)あり、草丈が
植物1: 10cm
植物2: 12cm
植物3: 14cm
植物4: 16cm
植物5: 18cm
であった場合、
全体から計算された平均値(=母集団の平均値)は14㎝であるのに対し、
ランダムに3つを抽出した標本をもとに計算される平均値は、植物1,2,3を選ぶと12cm、植物3,4,5を選ぶと16cmと、標本の選び方によって12~16cmと幅が生じてしまいます。
このような抽出された標本によるばらつきを扱うためには、確率的に標本データを捉える必要があり、標本分布という考え方が必要になってきます。
標本平均の確率分布
1/6の確率で植物1,2,3 … 標本平均12cm
1/6の確率で植物1,2,4 … 標本平均12.666cm
1/6の確率で植物1,2,5 … 標本平均13.333cm
1/6の確率で植物2,3,4 … 標本平均14cm
1/6の確率で植物2,3,5 … 標本平均14.666cm
1/6の確率で植物3,4,5 … 標本平均16cm
5.6.2. 母集団分布
統計的推測においては、抽出した標本から母集団の特徴、つまり母集団の従う分布母集団分布を知ることが目標となります。
この母集団分布から標本$X_1, X_2, … \(を抽出してくるので、各\)X_i$はこの母集団分布に従う確率変数だと考えることができます。
5.6.3. 母数
母集団が理論的・経験的によく知られた確率分布であることが分かっている場合、
例えば先ほど扱った交通事故の発生件数は発生確率が非常に低く、母集団分布がポアソン分布だと考えられる。
つまり、標本\(X_1, X_2, ... X_n\)は、ある\(\lambda\)を持つポアソン分布\(Po(\lambda)\)に従うと考えられる。
このとき、\(P(X_i=x)\)は\(f_\lambda(x)=e^{-\lambda}\dfrac{\lambda^x}{x!}\)となり、定数\(\lambda\)さえわかれば母集団について全て知ることができる。
このような事前に母集団分布=XX分布だと与えられている場合、その分布を決定するパラメータ(今回の場合\(\lambda\))が求めるべきものとなります。
統計的推測ではこのパラメータを母数と呼びます。
ポアソン分布の場合は\(\lambda\)でしたが、
母集団が正規分布\(N(\mu, \sigma^2)\)に従う場合は、平均\(\mu\)と分散\(\sigma^2\)の二つの母数によって分布が決定されるので、
母集団における平均と分散を求めることになります。
特に母集団分布について事前に分布を決めることができない場合は、母集団の平均(母平均)や中央値、最頻値、母集団の分散(母分散)、レンジなどを考え分析することになります。
5.6.4. 統計量
統計的推測では、抽出した標本からこの母数を推定することが1つの目的であり、母数を推定するために標本から計算された値を推定量と言います。
母集団分布について大まかなことが知りたい場合、まずは母数の中でも母平均\(\mu\)と母分散\(\sigma^2\)を推定することができると多くのことが分かります。
例えば、ある2集団それぞれの細かい母集団分布の形が分からなくても、母平均を比較することで全体的に差があるかどうかをある程度捉えることが出来ます。
あたりまえですが、母平均をいきなり求めることは出来ないので、代わりに標本サイズ\(n\)の標本\(X_1, X_2, ... X_n\)を観察し、
標本平均\(\bar{X}=(X_1+X_2+...+X_n)/n\)
をまずは用います。
各観測値\(X_i (i=1 \sim n)\)が母集団分布に従い、その期待値が母平均\(E(X_i)=\mu\)、分散が母分散\(V(X_i) = \sigma^2\)とすると、
標本平均の期待値\(E(\bar{X})\)は
\(E(\bar{X})=E((X_1+X_2+...+X_n)/n)=n\mu/n=\mu\)
となり、期待値が母平均\(\mu\)と一致します。
このように、標本から求めた推定量の期待値が、母数と一致するとき、その推定量は不偏性があるといい、不偏推定量であるといいます。
さらに、標本平均の分散\(V(\bar{X})\)を考えると、
\(V(\bar{X}) = V(\dfrac{1}{n}(X_1+X_2+...+X_n))=\dfrac{1}{n^2}V(X_1+X_2+...+X_n)=n\sigma^2/n^2=\sigma^2/n\)
となり、\(n\to\infty\)のとき、標本平均の分散は0に近付き、\(\bar{X}\)は\(\mu\)に確率収束していきます。(大数の法則を意味します。)
標本分散についてですが、標本分散は、
\(s^2=\dfrac{1}{n-1}\lbrace(X_1-\bar{X})^2+(X_2-\bar{X})^2+...+(X_n-\bar{X})^2\rbrace\)
で定義されます。
記述統計学のところでも触れた通り、\(n-1\)で割っているところが注意点です。
これは標本分散の期待値\(E(s^2)\)を計算すると、
\(E(s^2)=\sigma^2\)と母分散\(\sigma^2\)に一致するようになるからです。
したがって\(n-1\)を使って計算された\(s^2\)を母分散\(\sigma^2\)の不偏推定量、不偏分散と言います。
\(n-1\)ではなく\(n\)で割った\(S^2=\dfrac{1}{n}\lbrace(X_1-\bar{X})^2+(X_2-\bar{X})^2+...+(X_n-\bar{X})^2\rbrace\)も標本分散ではありますが、不偏でない標本分散となります。
標本平均や標本分散の様に、標本を要約し、母集団の母数のいろいろな推測に使用されるものを統計量と言います。
今回扱った標本平均\(\bar{X}\)や標本(不偏)分散\(s^2\)は、母平均\(\mu\)や母分散\(\sigma^2\)に対し、
\(E(\bar{X})=\mu\), \(E(s^2)=\sigma^2\)となるため、母集団と標本をつなぐ重要な統計量となります。
たとえば、ある実験で植物を栽培し、17個体の収穫量を測定した結果、
103, 95, 123, 72, 110, 121, 136, 93, 128, 99, 100, 112, 82, 98, 106, 94, 83 (g)だったとします。
この標本データから、この植物の収穫量の母平均\(\mu\)、母分散\(\sigma^2\)の見当をつけることを考えます。
このとき標本平均と不偏分散をmean関数やsd関数で調べてみると、
[ ]:
# 17個体の標本平均と不偏分散を求める
data <- c(103, 95, 123, 72, 110, 121, 136, 93, 128, 99, 100, 112, 82, 98, 106, 94, 83)
mean(data)
sd(data)
ということが分かります。
もしこの植物の母集団が正規分布している場合、正規分布の特徴から、95%程度の範囲で
\(\mu\pm2\sigma=69\sim137\)の範囲になることが推測できます。
(得られたデータもその範囲に収まっている。)
この様な形で標本データから母集団の特徴を推測することができるというわけです。
次回はこの部分をより細かく見ていきます。
5.7. 課題
今回の課題は下の課題ページを実施し、Pandaのテスト・クイズに記述してください。